UNIT 4 :SQL AND DATABASE PROJECT
UNIT 4: SQL AND DATABASE PROJECT
Key Unit Competency: To be able to apply Structured Query Language in RDBMS
and create a short database project
Introductory activity:
The school is requested to submit a report to the District indicating the data on
students, teachers, rooms and courses.
In groups, conduct a survey in your school and answer the following questions:
i. How many students are in the schools?
ii. How many student are in each class?
iii. How many boys are in the school? How many boys are in each class?
iv. How many are girls in the school? How girls are many in each class?
v. What is the number of teachers in the schools?
vi. How many teachers for Mathematics Subjects
vii. How many rooms are there in the school?
viii. How can you choose the courses that can be taught in the same
room?
ix. Show the number of students eligible to get National Identity card.
x. How do you think the school does such reporting according to these
criteria?
a. Design the entities student, teacher, room and course
b. Using the used RDBMS (MS Office Access) in the school computer
lab, create the database of the school with the 3 tables representing
the entities above.
c. Respond again to the sub questions in question a) by querying your
database. Are the answers the same? What is used to get the answerto each answer?
Activity 4.1:
4. Kabeza Company Ltd is running a business and wishes to manage
transactions in computerized way. The database of business contains
various entities including “Customers” (id, name, age, address, salary)
and orders (id,date,customer_id, amount) which are given here below.
Help your school to find a solution to get the following:
i. The highly paid employee
ii. The least paid employee
iii. The oldest employee
iv. The youngest employee
v. To generate total amount of income at a given day.
vi. To retrieve only the names and age of all employees
vii. To retrieve the average income at a given day.
“Customers” table:i. σage>=23 AND address≠ kigali(“Customers”)
Definition: relational algebra is the one whose operands are relations or variables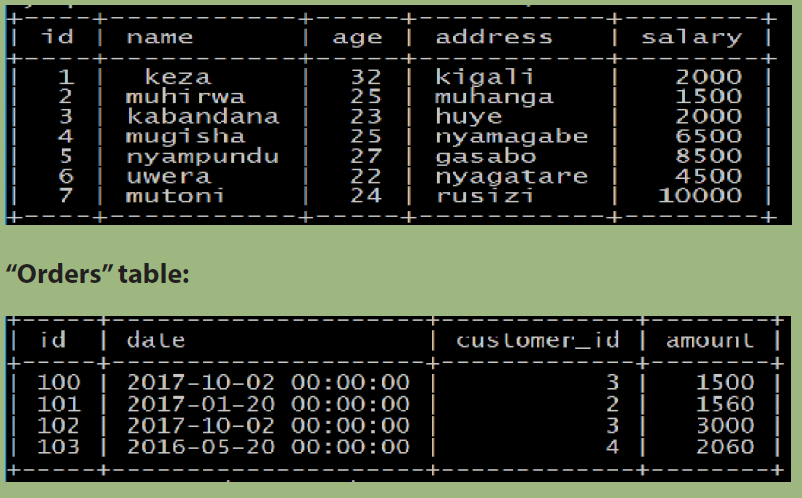
that represent relations.
4.1.1 Unary operations
By definition a unary operation is an operator that uses only one operand (relation).
In Relational algebra, the unary operations are selectionand projection
4.1.1.a Selection operation
Selection is a unary operation that selects records satisfying a given predicate
(criteria). It selects a subset of records. The lowercase Greek letter sigma (σ) is used to
denote selection. The selection condition appears as a subscript to σ. The argumentrelation is given in parenthesis following the σ.
Select Operation Notation Model
Syntax: σ selection_condition (Relation)
The selection condition or selection criterion can be any legally formed expression
that involves:
1. Constants (i.e, members of any attribute domain)
2. Attributes names
3. Arithmetic operators(+,*,/,-,%)
4. Comparisons/Relational operators : a. in mathematicl algebra(=,≠,<,>,≤,≥)
b.in relational algebra (=,<,<=,>,>=)
5. Logical operators( And,Or, Not)
Example of using selection operation within a relation: σ last_name=’Mugisha’
(“Customers”) where the table “Customers” in learning activities 4.1 is considered.The result is a binary relation listing all the “Customers” with the name Mugisha.
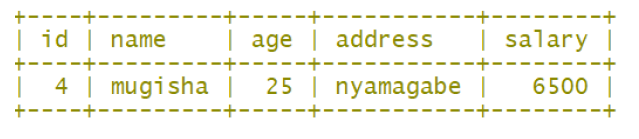
result of σ name=’Mugisha’ (“Customers”)
Application activity 4.1:
Using the table “Customers” in learning activities 4.1, what is the result of the
following statements?
i. σ Salary>2000 (“Customers”)ii. σage>=23 AND address≠ kigali(“Customers”)
4.1.1.b Projection operation
Activity 4.2
From the table “Customers”, display the following table with only twocolumns name and age
Result for π name,age (“Customers”)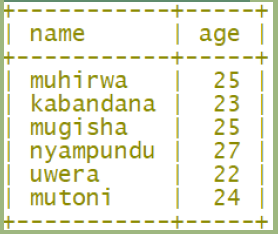
The PROJECT operation is another unary operation. This operation returns a set of
tuples containing a subset of the attributes in the original relation. Thus, we state
that the SELECT operation selects some rows and discards the others. The PROJECT
operation, on the other hand, selects some columns of the relation and discards
the other column. The PROJECT operation can be viewed as the vertical filter of the
relation.
The projection operation copies its arguments relation, but certain columns are left
out. The projection operation lists the desired attributes to appear in the result as a
subscript to π.
Projection is unary operation denoted by the Greek letter pi (π).
• Syntax: πattribute−list(r)
• Eg: Π attribute_1, attribute_2,…, attribute_n(Relation)Project Operation Notation Model:
Notice that if the projection produces two identical rows, the duplicate rows must be
removed since the relation is a set and it is not allowed to contain identical records.Eg:Example: Retrieve the suburbs that are stored in database
Application activity 4.2:
What is the result of the following statements?
i. π ID, Address (“Customers”)ii. π name,Salary(σSalary>5000) (“Customers”)
4.1.2 Binary operations
A binary operation is an operation that uses two operands (relations). In Relational
algebra, the binary operations are Cartesian product, Union operator, Set Difference,Intersection, Theta-join and Natural Join.
Activity 4.3:We have two relations, student and subject, as follows:
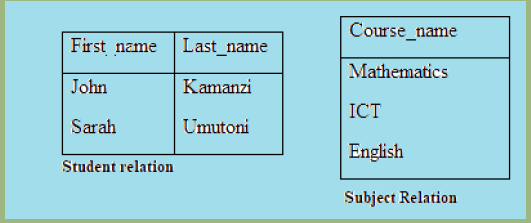
How can be generated the following table?
The Cartesian product of two relations, R1 and R2, is written in infix notation as
R1xR2. To define the final relation scheme, we need to use fully qualified attribute
names. Practically, it means we attach the name of the original relation in front of
the attribute. This way we can distinguish R1.A from R2.A. If R1(A1,A2,…,An) and
R2(A1,A2,…,An) are relations, then the Cartesian product R1xR2 is a relation with
a scheme containing all fully qualified attribute names from R1 and R2R1.A1,…
R1.An,R2.A1,….R2.An).
The records of Cartesian product are formed by combining each possible pair
of records: one from the R1 relation and another from the R2 relation. If there are
n1 records in R1 and n2 records in R2, then there are n1*n2 records in their Cartesianproduct.
The results of a Cartesian product is a relation whose scheme is a concatenation
of student scheme and subject scheme. In this case, there are no identical attribute
names. For that reason, we do not need to use the fully qualified attribute names.
Student relation contained 2 records, subject relation 3, therefore, the result has 6
records (2 times 3).
Note that the Cartesian product contains no more information than its components
contain together. However, the Cartesian product consumes much more memory
than the two original relations consume together. These are two good reasons why
Cartesian product should be de-emphasized, and used primarily for explanatory orconceptual purpose.
Application activity 4.3:
Carry out the following activity:
A. Union operator
Activity 4.4:
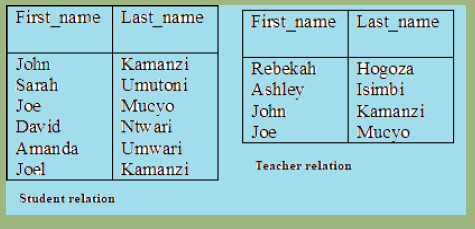
What was the operation performed in order to get this table?
The result of the query are all the people (students and teachers) appearing in either
or both of the two relations. Again, since relations are sets, duplicate values are
dropped.
The binary operation Union is denoted, as in set theory, by U. Union is intended
to bring together all of the facts from its arguments, however, the relational union
operator is intentionally not as general as the union operator in mathematics.
We cannot allow for an example that shows union of a binary and a ternary relation,
because the result of such union is not a relation. Formally, we must ensure that
union is applied to two union compatible relations. Therefore, for a union operatorR1UR2 to be legal,it is required that two conditions be held:
1. The relations R1 and R2 are of the same arity. Which means, they have the
same numbers of attributes.2. The domains of the ith attribute of R1 and ith attribute of R2 are the same.
Application activity 4.4:Carry out the following activity:
B. Set Difference
Activity 4.5:From the following table:

What is the operation performed in order to generate the following table?
The last fundamental operation we need to introduce is set difference. The set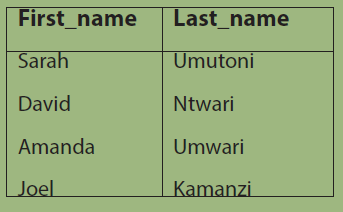
difference, denoted by - is a binary operator. To apply this operator to two relations,
it is required for them to be union compatible. The result of the expression R1-R2,
is a relation obtained by including all records from R1 that do not appear in R2. Of
course, the resulting relation contains no duplicate records.
Note that if the relations are union compatible, applying “set difference” to them is
allowed.
C. Intersection
The first operation we add to relational algebra is intersection, which is a binary
operation denoted by ∩ symbol. Intersection is not considered a fundamental
operation because it can be easily expressed using a pair of set difference operations.
Therefore, we require the input relations to union compatible.
After applying the intersection operator, we obtain a relation containing only those
records from r1 which also appear as records in r2.We do not need to eliminate
duplicate rows because the resulting relation cannot contain any (since neither of
the operands contain any).
Practical example:Consider relations R and S
D. Join operations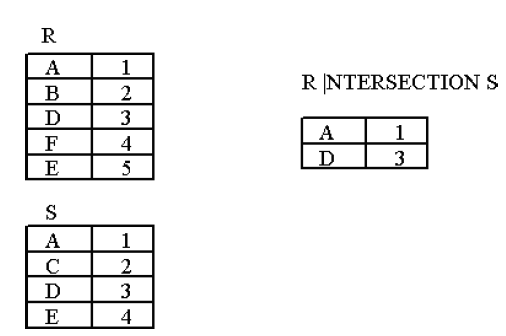
SQL Joins can be classified into Equi join and Non Equi join.
1. SQL Equi joins
It is a simple sql join condition which uses the equal sign as the comparison operator.
Two types of equi joins are SQL Outer join and SQL Inner join.
For example: You can get the information about a customer who purchased a
product and the quantity of product.
2. SQL Non equi joins
Types of Joins:
Join is a special form of cross product of two tables. It is a binary operation that
allows combining certain selections and a Cartesian product into one operation.
The The join operation forms a Cartesian product of its two arguments, performs a
selection forcing equality on those attributes that appear in both relation schemas,
and finally removes duplicate attributes. Following are the different types of joins:
Theta Join, Equi Join, Semi Join, Natural Join and Outer Joins
We will now discuss them one by one
1. Theta Join:
In theta join we apply the condition on input relation(s) and then only those selected
rows are used in the cross product to be merged and included in the output. It means
that in normal cross product all the rows of one relation are mapped/merged with
all the rows of second relation, but here only selected rows of a relation are made
cross product with second relation. It is denoted as RX S
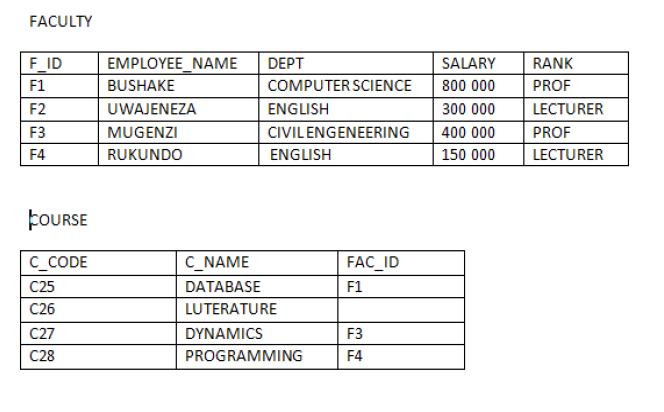
For example there are two relations of FACULTY and COURSE now first apply select
operation on the FACULTY relation for selection certain specific rows then these
rows will have a cross product with COURSE relation, so this is the difference in
between cross product and theta join. From this example the difference betweencross product and theta join becomes clear.
2. Equi¬ Join: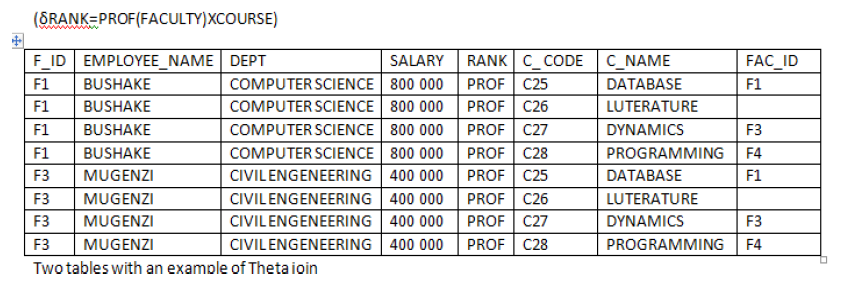
This is the most used type of join. In equi¬join rows are joined on the basis of values
of a common attribute between the two relations. It means relations are joined on
the basis of common attributes between them; which are meaningful. This means on
the basis of primary key, which is a foreign key in another relation. Rows having the
same value in the common attributes are joined. Common attributes appear twice in
the output. It means that the attributes, which are common in both relations, appear
twice, but only those rows, which are selected. Common attribute with the same
name is qualified with the relation name in the output. It means that if primary and
foreign keys of two relations are having the same names and if we take the equi ¬
join of both then in the output relation the relation name will precede the attribute
name. For Example, if we take the equi ¬ join of FACULTY and COURSE relations thenthe output would be
3. Natural Join:
This is the most common and general form of join. If we simply say join, it means
the natural join. It is same as equi¬ join but the difference is that in natural join,
the common attribute appears only once. Now, it does not matter which common
attribute should be part part of the output relation as the values in both are same.To join the tables use this symbol:

4. Outer Join:
This join condition returns all rows from both tables which satisfy the join condition
along with rows which do not satisfy the join condition from one of the tables.
The Outer Join has three forms:
a. Left Outer Join:
In a left outer join all the tuples of left relation remain part of the output. The tuples
that have a matching tuple in the second relation do have the corresponding tuple
from the second relation. However, for the tuples of the left relation, which do not
have a matching record in the right tuple, have null values against the attributes of
the right relation. Left outer join is the equi-join plus the non matching rows of theleft side relation having null against the attributes of right side relation.
The following example shows how Left Outer Join operation works:Consider the relation BOOK and relation STUDENT
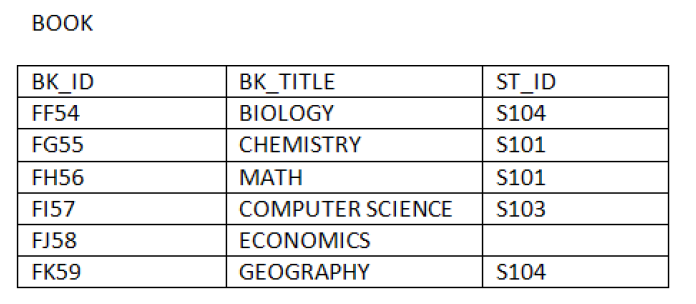
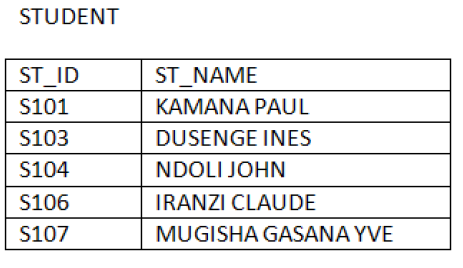
b. Right Outer Join: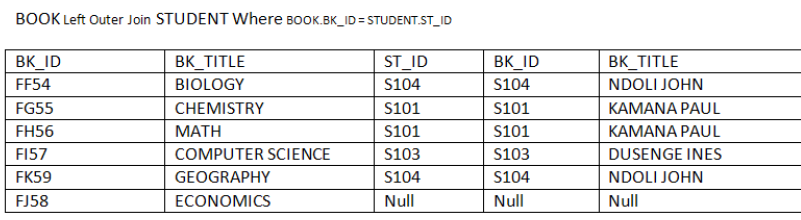
In right outer join all the tuples of right relation remain part of the output relation,
whereas on the left side the tuples, which do not match with the right relation,
are left as null. It means that right outer join will always have all the tuples of right
relation and those tuples of left relation which are not matched are left as Null. The
following example shows how Right Outer Join operation works:Consider the Relation BOOK and Relation STUDENT
c. Full Outer Join:
In outer join all the tuples of left and right relations are part of the output. It means
that all those tuples of left relation which are not matched with right relation are
left as null. Similarly all those tuples of right relation which are not matched with left
relation are left as null.
The following example shows how Right Outer Join operation works:Consider the relation BOOK and relation STUDENT
d. Division Operator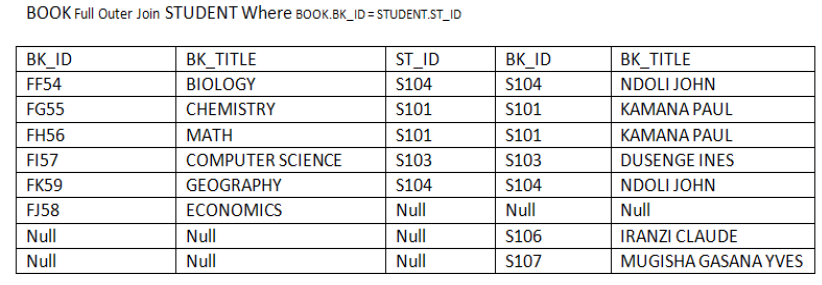
Division identifies attribute values from a relation that are paired with all of thevalues from another relation.
Application activity 4.5:
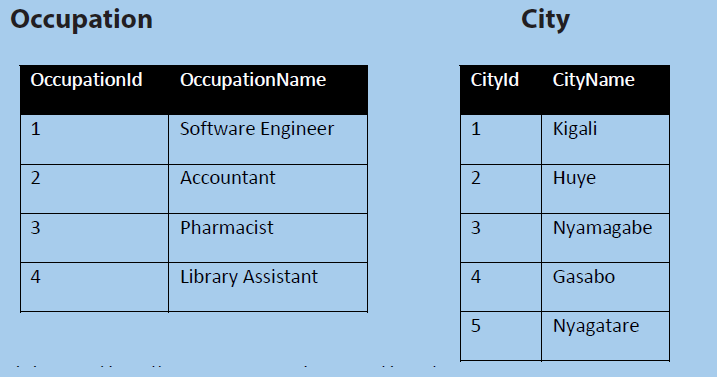
1. Solve the following relational expressions for these relations:User
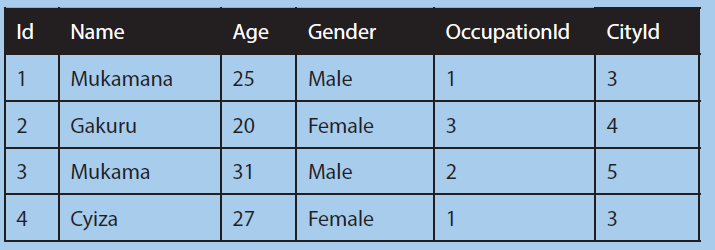
a. πName(δ(Age>25)(User)) same as δName(δAge>25)(User)
b. δ(Id>2∨Age!=31)(User)
c. δ(User.OccupationId=Occupation.OccupationId)(User X Occupation)
d. πName,Gender(δCityId=1User ⋈ City))
2. With clear example, differentiate unary operators and binary operators.
3. Use an example and explain projection and selection operations.4. Consider ABC database containing the following relations:
Representative (number, surname, firstname, committee, county)
Counties (code, name, region)
Regions(code, name)
Committees (number, name, president)
Formulate the following queries in relational algebra, in domain calculus and
in record calculus:
• Find the number and surname of the Representatives from the country
of Rwanda;
• Find the name and surname of representatives;
• Find the members of the finance committee;
• Find the name, surname, country and region of election of the
delegates of the finance committee;
• Find the regions in which representatives having the same surname
have been elected.
5. Consider the DEFG database schema with the relations:
Courses (number, faculty, coursetitle, tutornumber)
Students (number, surname, firstname, faculty)
Tutors (number. surname, firstname)
Exams (studentnumber, coursenumber, grade, date)
Studyplan( studentnumber, coursenumber, year)
* Formulate in relational algebra the queries that produce:
* The students who have gained an ‘A’ in at least one exam, showing, for
each of them, the first name, surname and the date of the first of such
occasions;
* For every course in the engineering faculty, the students who passed
the exam during the last session;
* The students who passed all the exams required by their respective
study plans;
* For every course in the literature faculty, students who passed the
exam with the highest grades;
* The students whose study plans require them to attend lectures only
in their own faculties;
* First name and surname of the students who have taken an exam witha tutor having the same surname as the student.
4.2 Structured Query language
Activity 4.6:
1. Consider the following relational schema of HIJK database;
Departments (Dept_Code (integer), name (text) , Budget (number)) Employees (SSN
(integer), first_name (text), last_name (text), Dept_Code (integer, foreign key) Write SQL
query to:
i. Create the above relations (tables)
ii. Add at least ten records
iii. Select the last name of all employees, without duplicates.
iv. Select all the data of employees whose first name is "Peter" or "Diane".
v. Retrieve the sum of all the departments’ budgets.
vi. Retrieve all the data of employees whose last name begins with letter
"U".
vii. Show the number of employees in each department (you only need to
show the department code and the number of employees).
viii. Select the name and last name of employees working for departments
with a budget greater than 6,000,000 (currency: Rwf)
ix. Show the departments with a budget larger than the average budget of
all the departments.
x. Add a new department called "Quality Assurance", with a budget of
4,000,000 (currency: Rwf) and departmental code 11. Add an employee
called "KAMANA" in that department, with SSN 847-21-9811.
xi. Reduce the budget of all departments by 10%.xii. Delete from the table all employees in the IT department (code 14).
4.2.0. Introduction
SQL which is an abbreviation for Structured Query Language, is a language to
request data from a database, to add, update, or remove data within a database, or
to manipulate the metadata of the database.
Commonly used statements are grouped into the following categories:
DML: Data Manipulation LanguageDDL: Data Definition Language
DCL: Data Control Language
4.2.1 Data Definition Language (DDL)
a. To create a new database, the SQL query used is CREATE DATABASE
The Syntax is:
create database databasename;
Always database name should be unique within the RDBMS. Example of a query to
create a database called XYZLtdCREATE DATABASE XYZLtd; In MYSQL, it will look like the following:
Make sure that the user has admin privilege before creating any database.
b. To display the list of all databases created, the SQL query is SHOW
databases;
Once a database is created, the user can check it in the list of databases as follows:
Show databases;If the RDBMS used is MYSQL, the result will look like this:
c. Before using a database, the SQL command USE helps to select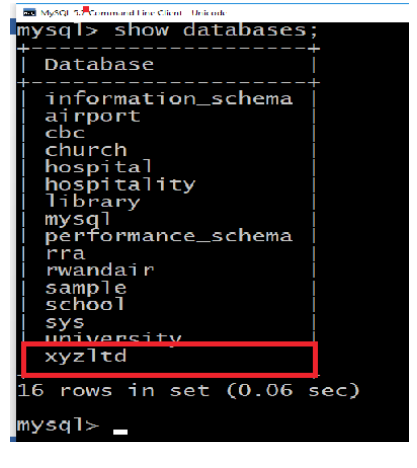
the name of the database.
The SQL USE statement is used to select any existing database in the SQL schema.
Syntax: The basic syntax of the USE statement is as shown below: Always the
database name should be unique within the RDBMS. Now, if the user wants to work
with the XYZLtd database, then he/shecan execute the following SQL commandand start working with the School database.
d. After creating a database and entering in it, there is a need now
to create table
Creating a basic table involves naming the table and defining its columns and each
column’s data type. The SQL CREATE TABLE statement is used to create a new table.
the basic syntax of CREATE TABLE statement is as follows:
create table table_name (column1 datatype, column2 datatype, column3 datatype,
..... columnn datatype,
primary key( one or more columns ) );
CREATE TABLE is the keyword telling the database system what you want to do. In
this case, you want to create a new table. The unique name or identifier for the table
follows the CREATE TABLE statement.
Then in brackets comes the list defining each column in the table and what sort of
data type it is. The syntax becomes clearer with an example below.
Activity 4.7:
The following SQL query creates a “Customers” table with ID as primary key and NOT
NULL and thereafter, when the table was successfully created, the message “Query OK,o rows affected (0.48 sec)” is displayed. See below.
The user can verify if the table has been created successfully by looking at the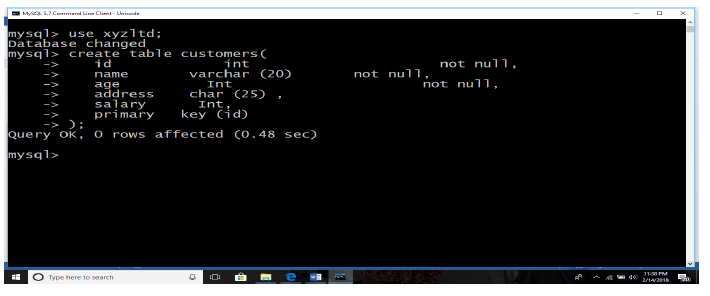
message displayed by the SQL server, otherwise he/she can use DESC command asfollows:
Now, “Customers” table is created and available in database. It can be used to store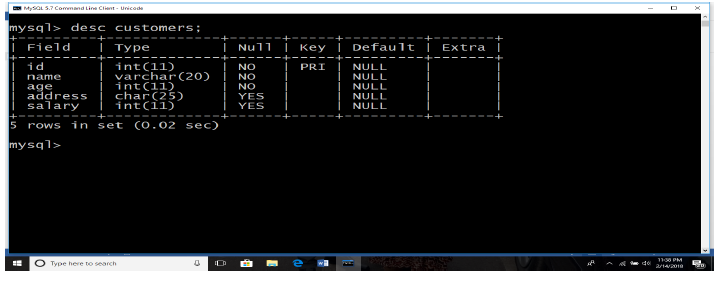
required information related to “Customers”.
Notice that DESC is the same as DESCRIBE is some RDBMS.
e. Create Table Using another Table:
A copy of an existing table can be created using a combination of the CREATE TABLE
statement and the SELECT statement.
The new table has the same column definitions. All columns or specific columns can
be selected.
When you create a new table using existing table, new table would be populated
using existing values in the old table.
The basic syntax for creating a table from another table is as follows:create table new_table_name as like existing_table_name [ where ]
Example:
To create a table called SALARY having the same attributes like table “Customers”,
writeCreate table salary like “Customers”;

The structure of SALARY is displayed in the following interface.
f. To remove a table from a database, use the SQL Command “DROP TABLE”.
The SQL DROP TABLE statement is used to remove a table definition and all its data.
Notice that the user has to be careful while using this command because once
a table is deleted then all the information available in the table would also be lost
forever.The Basic syntax of DROP TABLE statement is as follows:
Example:
DROP TABLE “Customers”;
To make sure that the table has been removed, check withDESC “Customers”; and the answer will be like the following:
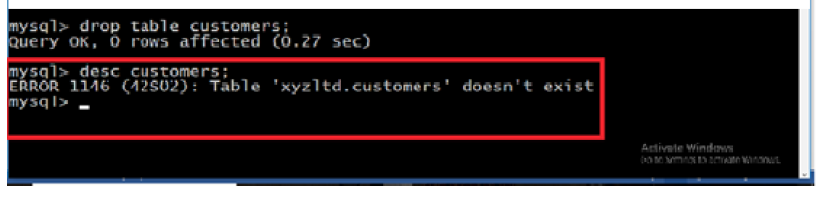
“CUSTOMERS” Relation
g. To add, delete or modify columns in an existing table, use the SQL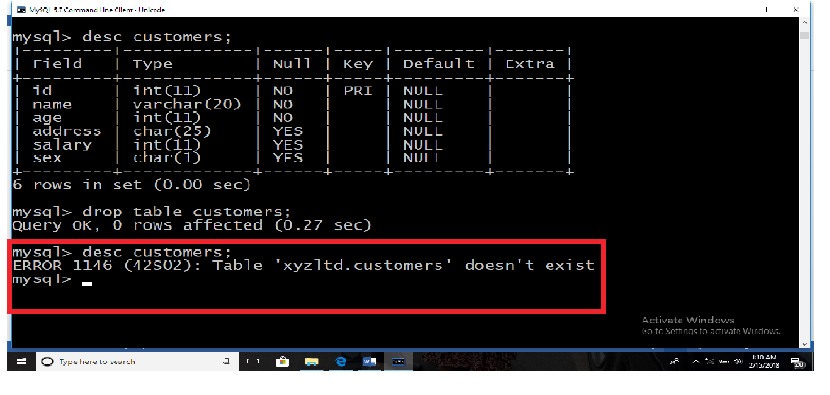
Command ALTER TABLE followed by either ADD or DROP or MODIFY.
ALTER TABLE command can also be used to add and drop various constraints on anexisting table.
The basic syntax of ALTER TABLE to add a new column in an existing table is as
follows:alter table table_name add column_name datatype;
The basic syntax of ALTER TABLE to DROP COLUMN in an existing table is as follows:alter table table_name drop column column_name;
The basic syntax of ALTER TABLE to change the DATA TYPE of a column in a table is
as follows:alter table table_name modify column column_name datatype;
The basic syntax of ALTER TABLE to add a NOT NULL constraint to a column in a
table is as follows:alter table table_name modify column_name datatype not null;
The basic syntax of ALTER TABLE to ADD UNIQUE CONSTRAINT to a table is as
follows:
alter table table_nameadd constraint myuniqueconstraint unique(column1, column2...);
The basic syntax of ALTER TABLE to ADD CHECK CONSTRAINT to a table is as follows:
alter table table_nameadd constraint myuniqueconstraint check (condition);
The basic syntax of ALTER TABLE to ADD PRIMARY KEY constraint to a table is as
follows:
alter table table_name add constraint myprimarykey primary key (column1,column2...);
The basic syntax of ALTER TABLE to DROP CONSTRAINT from a table is as follows:alter table table_name drop constraint myuniqueconstraint;
If you’re using MySQL, the code is as follows:alter table table_name drop index myuniqueconstraint;
The basic syntax of ALTER TABLE to DROP PRIMARY KEY constraint from a table is
as follows:alter table table_name drop constraint myprimarykey;
If you’re using MySQL, the code is as follows:alter table table_name drop primary key;
Application activity 4.7:
You are given a flat database named “Library”, with a relation Book (ISBN (Text,
primary key), title (text), author (text), pages (integer), and price (integer)) Create
this database and relation, then insert at least five records.
4.2.1.a SQL Constraints
Activity 4.8:
Consider “Customers” relation, perform the following tasks;
i. Add new column “sex”
ii. Change the datatype of salary to decimals
iii. Add “Not null” constraint to age field (column)
iv. Remove the column “sex”
v. Drop “not null” constraint from age field.
Constraints are the rules enforced on data columns of a table. These are used to limit
the type of data that can go into a table. This ensures the accuracy and reliability of
the data in the database.
Constraints could be column level or table level. Column level constraints are applied
only to one column whereas table level constraints are applied to the whole table.
Following are commonly used constraints available in SQL. These constraints have
already been discussed inSQL - RDBMS
Following are commonly used constraints available in SQL:
• Not null constraint: ensures that a column cannot have null value.
• Default constraint: provides a default value for a column when none is
specified.
• Unique constraint: ensures that all values in a column are different.
• Primary key: uniquely identified each rows/records in a database table.
• Foreign key: uniquely identified a row/record in any other database table.
• Check constraint: the check constraint ensures that all values in a column
satisfy certain conditions.
• Index: use to create and retrieve data from the database very quickly.• NOT NULL Constraint:
By default, a column can hold NULL values. If the user does not want a column to
have a NULL value, then he/she needs to define such constraint on this column
specifying that NULL is now not allowed for that column. A NULL is not the same as
no data, rather, it represents unknown data.
Example:
For example, the following SQL query creates a new table called “CUSTOMERS” and
adds five columns, three of which, ID and NAME and AGE, specify not to acceptNULLs:
create table “Customers”(
id int not null,
name varchar (20) not null,
age int not null,
address char (25) ,
salary Int,
primary key (id));
a. DEFAULT Constraint:
The DEFAULT constraint provides a default value to a column when the INSERT INTO
statement does not provide a specific value.
Example:
For example, the following SQL creates a new table called “CUSTOMERS” and adds
five columns. Here, SALARY column is set to 5000 by default, so in case INSERT INTO
statement does not provide a value for this column, then by default this columnwould be set to 5000.
If “Customers” table has already been created, then to add a DEFAULT constraint to
SALARY column, write a statement similar to the following:
Drop “Default” Constraint:
To drop a DEFAULT constraint, use the following SQL:
b. UNIQUE Constraint:
The UNIQUE Constraint prevents two records from having identical values in a
particular column. In the “Customers” table, for example, you might want to prevent
two or more people from having identical age.
Example:
For example, the following SQL creates a new table called “CUSTOMERS” and adds
five columns. Here, AGE column is set to UNIQUE, so that you cannot have tworecords with same age:
If “CUSTOMERS” table has already been created, then to add a UNIQUE constraint to
AGE column, you would write a statement similar to the following
The user can also use the following syntax, which supports naming the constraint in
multiple columns as well:
Drop a UNIQUE Constraint:
To drop a UNIQUE constraint, use the following SQL:

If you are using MySQL, then you can use the following syntax
c. PRIMARY Key:
A primary key is a field in a table which uniquely identifies each row/record in a
database table. Primary keys must contain unique values. A primary key column
cannot have NULL values.
A table can have only one primary key, which may consist of single or multiple fields.
When multiple fields are used as a primary key, they are called a composite key.
If a table has a primary key defined on any field(s), then it is impossible to have two
records having the same value of that field(s).
Notice that these concepts can be used while creating database tables.The syntax to define ID attribute as a primary key in a “CUSTOMERS” table is:
To create a PRIMARY KEY constraint on the “ID” column when “CUSTOMERS” table
already exists, use the following SQL syntax:
Alter table customers add primary key (ID);
Notice that to use the ALTER TABLE statement to add a primary key, the primary key
column(s) must already have been declared to not contain NULL values (when the
table was first created).
For defining a PRIMARY KEY constraint on multiple columns, use the following SQLsyntax:
To create a PRIMARY KEY constraint on the “ID” and “NAMES” columns when
“CUSTOMERS” table already exists, use the following SQL syntax:
To delete the Primary Key constraints from the table,
, use the Syntax:
d. FOREIGN Key:
A foreign key is a key used to link two tables together. This is sometimes called a
referencing key.
The Foreign Key is a column or a combination of columns, whose values match aPrimary Key in a different table.
The relationship between 2 tables matches the Primary Key in one of the tables with
a Foreign Key in the second table.
If a table has a primary key defined on any field(s), then you cannot have two records
having the same value of that field(s).
Example:
Consider the structure of the two tables as follows:“CUSTOMERS” table:

ORDERS table:
If ORDERS table has already been created, and the foreign key has not yet been, use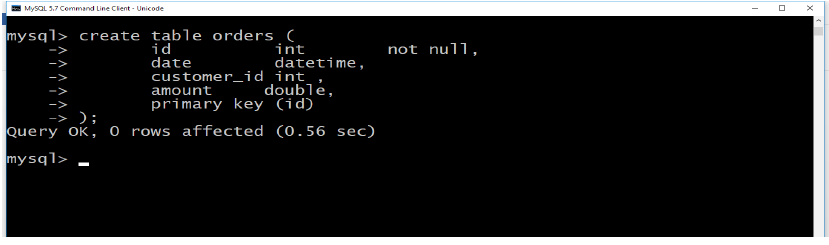
the syntax for specifying a foreign key by altering a table.
Drop a FOREIGN KEY Constraint:
To drop a FOREIGN KEY constraint, use the following SQL:
e. CHECK Constraint:
The CHECK Constraint enables a condition to check the value being entered into a
record. If the condition evaluates to true, the record violates the constraint and isn’t
entered into the table.
Example:
For example, the following SQL creates a new table called “CUSTOMERS” and adds
five columns. Here, we add a CHECK with AGE column, so that you cannot have anyCustomer below 18 years:
If “Customers” table has already been created, then to add a CHECK constraint to AGE
column, you would write a statement similar to the following:
You can also use following syntax, which supports naming the constraint and
multiple columns as well:
Drop a CHECK Constraint:
To drop a CHECK constraint, use the following SQL. This syntax does not work withMySQL:
Dropping Constraints:
Any constraint that you have defined can be dropped using the ALTER TABLE
command with the DROP CONSTRAINT option.
For example, to drop the primary key constraint in the EMPLOYEES table, you canuse the following command:
Some implementations may provide shortcuts for dropping certain constraints. For
example, to drop the primary key constraint for a table in Oracle, you can use thefollowing command:
Some implementations allow you to disable constraints. Instead of permanently
dropping a constraint from the database, you may want to temporarily disable theconstraint, and then enable it later.
Integrity Constraints:
Integrity constraints are used to ensure accuracy and consistency of data in a
relational database. Data integrity is handled in a relational database through the
concept of referential integrity.
There are many types of integrity constraints that play a role in referential integrity
(RI). These constraints include Primary Key, Foreign Key, Unique Constraints and
other constraints mentioned above.
4.2.2 Data Manipulation Language (DML)
A. Insert into command
The SQL INSERT INTO Statement is used to add new rows of data into a table in the
database.
There are two basic syntaxes of INSERT INTO statement as follows:
insert into table_name (column1, column2, column3,...columnn)] values
(value1, value2, value3,...valuen);
Here, column1, column2,..columnN are the names of the columns in the table into
which you want to insert data.
You may not need to specify the column(s) name in the SQL query if you are adding
values for all the columns of the table. But make sure the order of the values is in the
same order as the columns in the table. The SQL INSERT INTO syntax would be asfollows:
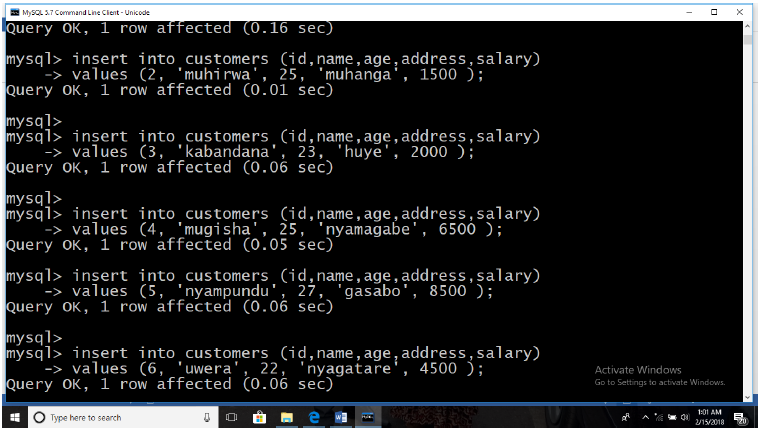
Activity 4.9:
Create/ insert six records in “Customers” table (relation). Use two possibleways to insert records (tuples) in a table:
First method:
Second method:
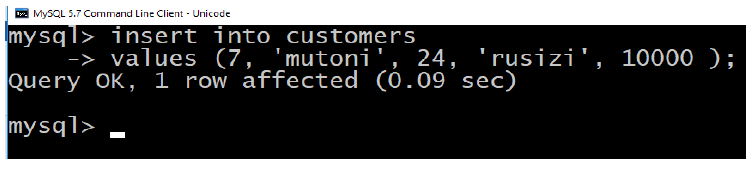
All the above statements would produce the following records in “Customers” table:
B. Select statement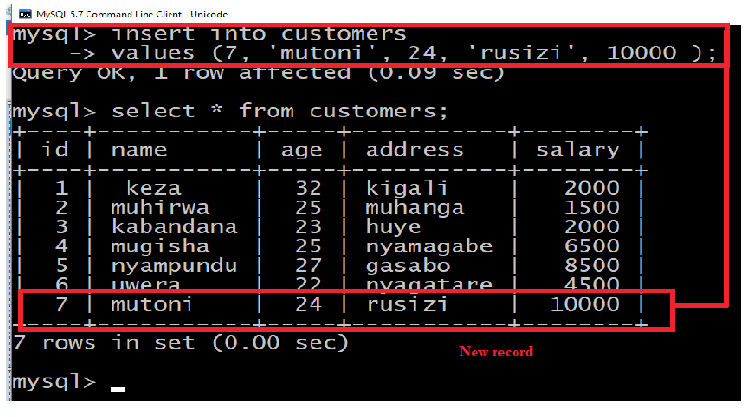
The SELECT statement is used to select data from a database. The data returned is
stored in a result table, called the result-set.SELECT Syntax
Here, column1, column2,... are the field names of the table you want to select data
from. If you want to select all the fields available in the table, use the following syntax:
SELECT * (Select all)
The following SQL statement selects all the columns from the ““Customers”” table:SELECT * FROM “Customers”;
The SQL SELECT DISTINCT Statement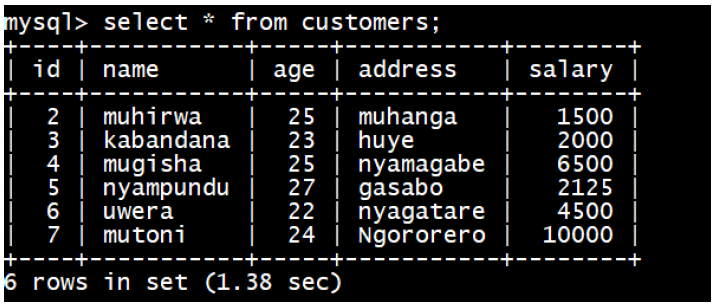
The SELECT DISTINCT statement is used to return only distinct (different) values.
Inside a table, a column often contains many duplicate values; and sometimes you
only want to list the different (distinct) values. The SELECT DISTINCT statement isused to return only distinct (different) values.
SELECT DISTINCT Syntax
SELECT Example
The following SQL statement selects all (and duplicate) values from the “Address”
column in the ““Customers”” table:
Example
SELECT Address FROM “Customers”;
WHERE Clause Example
The following SQL statement selects all the “Customers” from the address “Muhanga”,
in the “Customers” table:
Example
SELECT * FROM “Customers”
WHERE Address=’Muhanga’;
The SQL AND, OR and NOT Operators
The WHERE clause can be combined with AND, OR, and NOT operators. The AND,
OR operators are used to filter records based on more than one condition: The AND
operator displays a record if all the conditions separated by AND are TRUE. The OR
operator displays a record if any of the conditions separated by OR is TRUE. The NOToperator displays a record if the condition(s) is NOT TRUE.
AND Example
The following SQL statement selects all fields from ““Customers”” where address is
“Nyamagabe” AND address is “Huye”:
Example
SELECT * FROM “Customers” WHERE Address=’Nyamagabe’ AND Address=’Huye’;
OR Example
The following SQL statement selects all fields from “Customers” where address is“Huye” OR “Nyamagabe”;
Example for NOT operator
The following SQL statement selects all fields from “Customers” where address is NOT“Nyamagabe”:
ExampleSELECT * FROM “Customers” WHERE NOT Address=’Nyamagabe’;
You can also combine the AND, OR and NOT operators.
The following SQL statement selects all fields from ““Customers”” where address is
“Nyamagabe” AND address must be “Huye” OR “Nyamagabe” (use parenthesis to form
complex expressions):
Example:
SELECT * FROM “Customers” WHERE Address=’Nyamagabe’ AND (Address=’Huye’ ORAddress=’Nyamagabe’);
The following SQL statement selects all fields from “Customers” where address is NOT
“Nyamagabe” and NOT “GASABO”:
Example:SELECT * FROM “Customers” WHERE NOT Address=”Nyamagabe” AND NOT Address=”GASABO”;
Application activity 4.6:
You are given a flat database named “Library”, with a relation Book (ISBN (Text, primary
key), title (text), author (text), pages (integer), and price (integer))
i. Create this database and relation, then insert at least five records.
ii. Retrieve ISBN and price of books written by “Bigirumwami”
iii. Retrieve books whose price is between 30,000 and 200,000 Rwf
iv. Select title and pages of all books
v. Show the books that have more than 300 pages or books that cost more
than 4,000 Rwf
vi. Retrieve books written by authors whose name is started by A, B or C.
vii. Order the books ‘titles from A to Z.
viii. Retrieve top three books.
ix. Delete books which have less than 50 pagesx. Delete books written by “Kagame”.
C. Aggregate functions:
1. SQL COUNT Function- The SQL COUNT aggregate function is used to
count the number of rows in a database table.
2. SQL MAX Function- The SQL MAX aggregate function allows us to select
the highest (maximum) value for a certain column.
3. SQL MIN Function- The SQL MIN aggregate function allows us to select
the lowest (minimum) value for a certain column.
4. SQL AVG Function- The SQL AVG aggregate function selects the average
value for certain table column.
5. SQL SUM Function- The SQL SUM aggregate function allows selecting the
total for a numeric column.6. SQL COUNT Function
SQL COUNT Function is the simplest function and very useful in counting the numberof records, which are expected to be returned by a SELECT statement.
Similarly, if you want to count the number of records that meet a given criteria, it can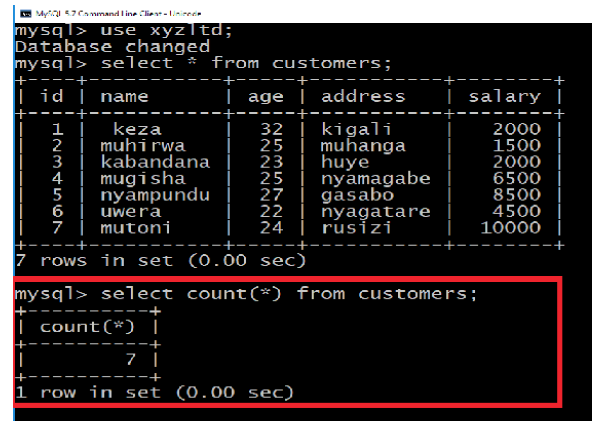
be done as follows to count records whose salary is 2000:
Notice that all the SQL queries are case insensitive, so it does not make any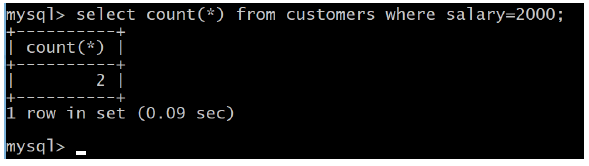
difference if you write SALARY or salary in WHERE condition.
SQL MAX Function
SQL MAX function is used to find out the record with maximum value among arecord set.
SQL MIN Function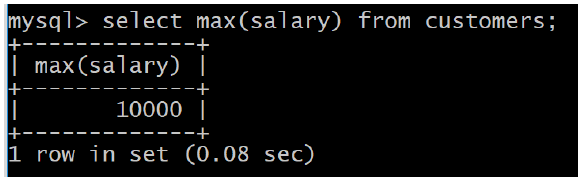
SQL MIN function is used to find out the record with minimum value among a recordset.
You can use MIN Function along with MAX function to find out minimum value as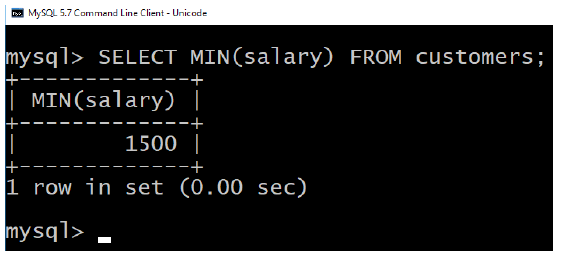
well.
SQL AVG Function
SQL AVG function is used to find out the average of a field in various records.
7. SQL SUM Function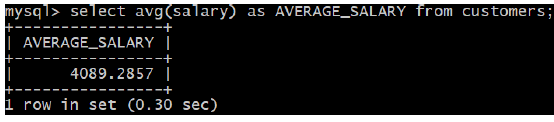
SQL SUM function is used to find out the sum of a field in various records.
Application activity 4.7: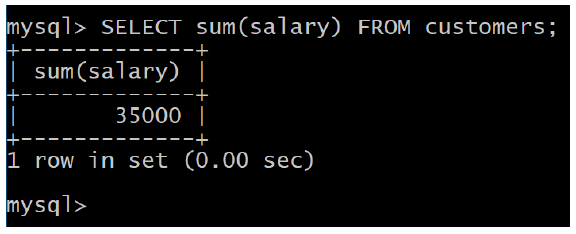
You are given a flat database named “Library”, with a relation Book (ISBN (Text,
primary key), title (text), author (text), pages (integer), and price (integer))
i. Create this database and relation, then insert at least five records.
ii. Retrieve the amount to get when all books are sold.
iii. Retrieve the most expensive book.
iv. Select the least expensive book
v. Show the total number of the books in book relation.vi. Find the average price of the books
D. String Expressions
SQL string functions are used primarily for string manipulation. The following tabledetails the important string functions:
a. CONCAT (str1,str2,...)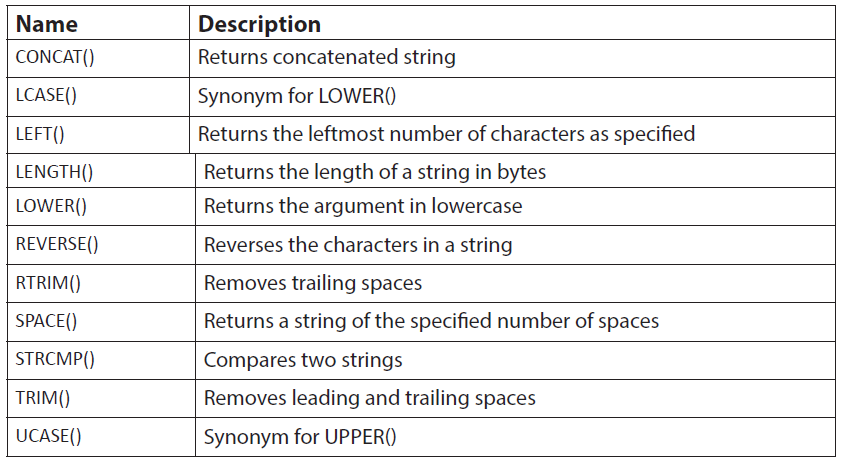
Returns the string that results from concatenating the arguments. May have one or
more arguments. If all arguments are non-binary strings, the result is a non-binary
string. If the arguments include any binary strings, the result is a binary string. A
numeric argument is converted to its equivalent binary string form; if you want toavoid that, you can use an explicit type cast, as in this example:

b. LEFT(str,len)
Returns the leftmost len characters from the string str, or NULL if any argument isNULL.
c. LENGTH (str)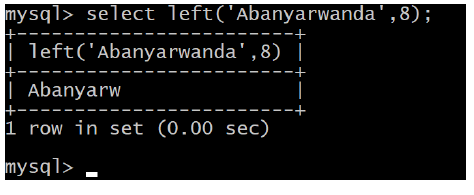
Returns the length of the string str measured in bytes. A multi-byte character counts
as multiple bytes. This means that for a string containing five two-byte characters,LENGTH
returns 10, whereas CHAR_LENGTH
d. LOWER(str)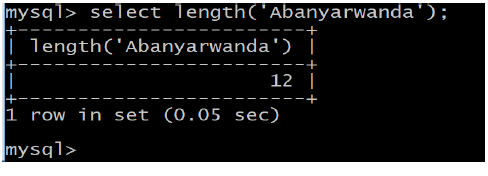
Returns the string str with all characters changed to lowercase according to thecurrent character set mapping.
e. REVERSE(str)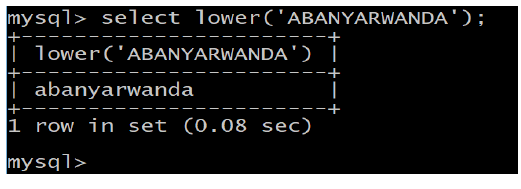
Returns the string str with the order of the characters reversed.
Application activity 4.8: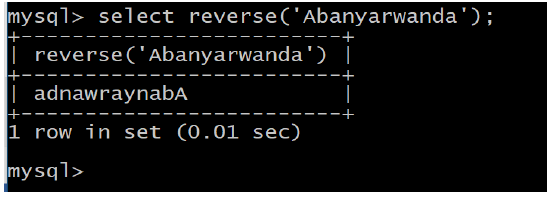
You are given a flat database named “Library”, with a relation Book (ISBN (Text,
primary key), title (text), author (text), pages (integer), and price (integer))
i. Find the length of the title of the book which has 35050115-30 as ISBN
ii. Reverse the name of the author who wrote the book “Imigenzo
n’imiziririzo ya Kinyarwanda”.
iii. Compare the names “Aloys” and “Alexis”.
iv. Change “Ndi umunyarwanda” in upper case.
v. Change “HELP EACH OTHER” in lower case
E. SQL JOINS
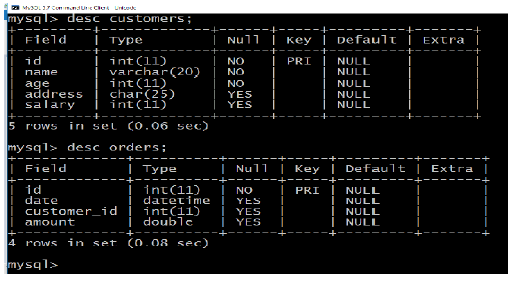
The SQL Joins clause is used to combine records from two or more tables in a
database. A JOIN is a mean for combining fields from two tables by using values
common to each.Consider “Customers” and orders tables as follows:
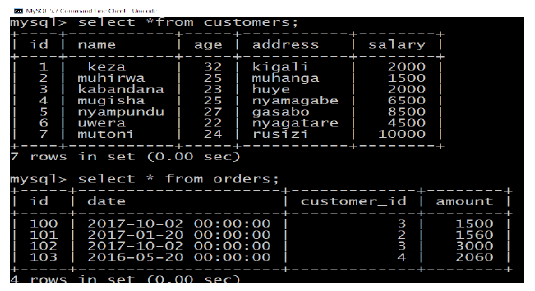
These two tables (relations) have the following records:
Now, let us join these two tables in our SELECT statement as follows:

This would produce the following result:
Here, it is noticeable that the join is performed in the WHERE clause. Several operators
can be used to join tables, such as =, <, >, <>, <=, >=,! =, BETWEEN, LIKE, and NOT;
they can all be used to join tables. However, the most common operator is the equalsymbol.
SQL Join Types:
There are different types of joins available in SQL:
Inner join: returns rows when there is a match in both tables.
Left join: returns all rows from the left table, even if there are no matches in the right
table.
Right join: returns all rows from the right table, even if there are no matches in the
left table.
Full join: returns rows when there is a match in one of the tables.
Self-join: is used to join a table to itself as if the table were two tables, temporarily
renaming at least one table in the sql statement.
Cartesian join: returns the Cartesian product of the sets of records from the two ormore joined tables.
1. INNER JOIN
The most frequently used and important of the joins is the INNER JOIN. They are also
referred to as an EQUIJOIN.
The INNER JOIN creates a new result table by combining column values of two
tables (table1 and table2) based upon the join-predicate. The query compares each
row of table1 with each row of table2 to find all pairs of rows which satisfy the joinpredicate.
When the join-predicate is satisfied, column values for each matched pairof rows of A and B are combined into a result row.
The basic syntax of INNER JOIN is as follows:

2. LEFT JOIN
The SQL LEFT JOIN returns all rows from the left table, even if there are no matches
in the right table. This means that if the ON clause matches 0 (zero) records in right
table, the join will still return a row in the result, but with NULL in each column from
right table.
This means that a left join returns all the values from the left table, plus matchedvalues from the right table or NULL in case of no matching join predicate.
Syntax:The basic syntax of LEFT JOIN is as follows:

3. RIGHT JOIN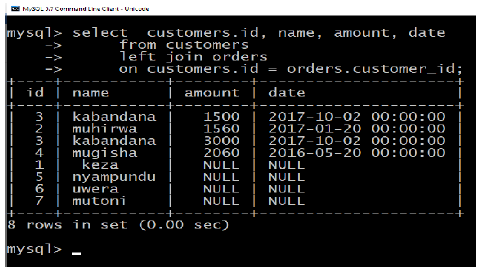
The SQL RIGHT JOIN returns all rows from the right table, even if there are no matches
in the left table. This means that if the ON clause matches 0 (zero) records in left
table, the join will still return a row in the result, but with NULL in each column from
left table.
This means that a right join returns all the values from the right table, plus matched
values from the left table or NULL in case of no matching join predicate.The basic syntax of RIGHT JOIN is as follows:

4. FULL JOIN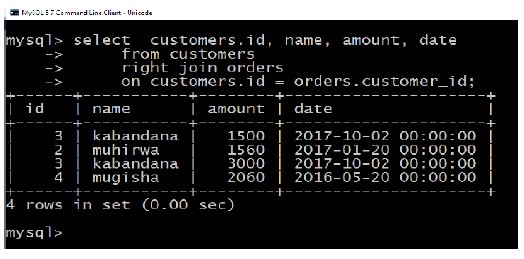
The SQL FULL JOIN combines the results of both left and right outer joins.
The joined table will contain all records from both tables, and fill in NULLs for missing
matches on either side.The basic syntax of FULL JOIN is as follows:

If your DBMS does not support FULL JOIN like MySQL does not support FULL JOIN,
then you can use UNION ALL clause to combine two JOINS as follows:
5. SELF JOIN
The SQL SELF JOIN is used to join a table to itself as if the table were two tables,
temporarily renaming at least one table in the SQL statement.The basic syntax of SELF JOIN is as follows:

6. CARTESIAN JOIN
The CARTESIAN JOIN or CROSS JOIN returns the Cartesian product of the sets of
records from the two or more joined tables. Thus, it equates to an inner join where
the join-condition always evaluates to True or where the join condition is absent
from the statement.The basic syntax of INNER JOIN is as follows:

F. SQL Unions Clause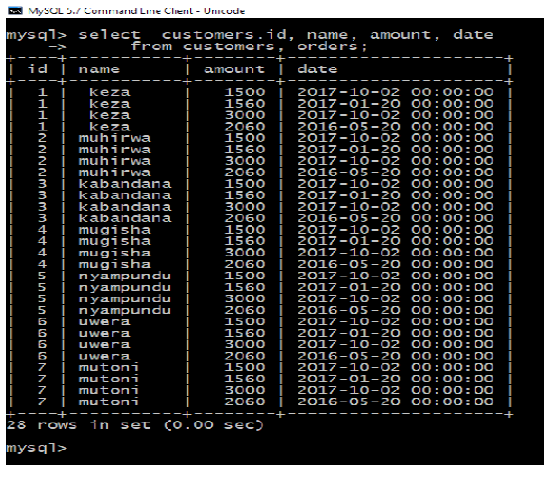
The SQL UNION clause/operator is used to combine the results of two or more
SELECT statementswithout returning any duplicate rows.
To use UNION, each SELECT must have the same number of columns selected, the
same number of column expressions, the same data type, and have them in the
same order, but they do not have to be the same length.The basic syntax of UNION is as follows:

1. The UNION ALL Clause:
The UNION ALL operator is used to combine the results of two SELECT statements
including duplicate rows. The same rules that apply to UNION apply to the UNIONALL operator.
The basic syntax of UNION ALL is as follows:

There are two other clauses (i.e., operators), which are very similar to UNION
clause: SQLINTERSECT Clause: is used to combine two SELECT statements, but
returns rows only from the first SELECT statement that are identical to a row in the
second SELECT statement. SQLEXCEPT Clause: combines two SELECT statements and
returns rows from the first SELECT statement that are not returned by the second
SELECT statement.
2. INTERSECT Clause
The SQL INTERSECT clause/operator is used to combine two SELECT statements,
but returns rows only from the first SELECT statement that are identical to a row in
the second SELECT statement. This means INTERSECT returns only common rows
returned by the two SELECT statements.
Just as with the UNION operator, the same rules apply when using the INTERSECT
operator. MySQL does not support INTERSECT operatorThe basic syntax of INTERSECT is as follows:

Example:
3. EXCEPT Clause
The SQL EXCEPT clause/operator is used to combine two SELECT statements and
returns rows from the first SELECT statement that are not returned by the second
SELECT statement. This means EXCEPT returns only rows, which are not available in
second SELECT statement.
Just as with the UNION operator, the same rules apply when using the EXCEPT
operator. MySQL does not support EXCEPT operator.The basic syntax of EXCEPT is as follows:

Example:
Select statement with Alias
You can rename a table or a column temporarily by giving another name known asalias.
The use of table aliases means to rename a table in a particular SQL statement. The
renaming is a temporary change and the actual table name does not change in the
database. The column aliases are used to rename a table’s columns for the purpose
of a particular SQL query.The basic syntax of table alias is as follows:

The basic syntax of column alias is as follows:


Following is the usage of column alias:

G. SQL TRUNCATE TABLE
The SQL TRUNCATE TABLE command is used to delete complete data from an
existing table.
You can also use DROP TABLE command to delete complete table but it would
remove complete table structure form the database and you would need to recreate
this table once again if you wish you store some data.The basic syntax of TRUNCATE TABLE is as follows:

Example:
H. SQL HAVING CLAUSE
The HAVING clause enables you to specify conditions that filter which group results
appear in the final results. The WHERE clause places conditions on the selected
columns, whereas the HAVING clause places conditions on groups created by the
GROUP BY clause.The following is the position of the HAVING clause in a query:
The HAVING clause must follow the GROUP BY clause in a query and must also
precede the ORDER BY clause if used. The following is the syntax of the SELECTstatement, including the HAVING clause:
Example:
Following is the example, which would display record for which similar age countwould be more than or equal to 2:
I . SQL SUB QUERIES
A Subquery or Inner query or Nested query is a query within another SQL query and
embedded within the WHERE clause.
A subquery is used to return data that will be used in the main query as a condition
to further restrict the data to be retrieved.
Subqueries can be used with the SELECT, INSERT, UPDATE, and DELETE statements
along with the operators like =, <, >, >=, <=, IN, BETWEEN etc.
There are a few rules that subquery must follow:
* Subquery must be enclosed within parentheses.
* A subquery can have only one column in the SELECT clause, unless multiple
columns are in the main query for the subquery to compare its selected
columns.
* Subqueries that return more than one row can only be used with multiple
value operators, such as the IN operator.
* A subquery cannot be immediately enclosed in a set function.
* The BETWEEN operator cannot be used with a subquery; however, the
BETWEEN operator can be used within the subquery.
I.1. Subqueries with the SELECT Statement:Subqueries are most frequently used with the SELECT statement. The basic syntax
is as follows:

I.2. Subqueries with the INSERT Statement:
Subqueries also can be used with INSERT statements. The INSERT statement uses the
data returned from the subquery to insert into another table. The selected data inthe subquery can be modified with any of the character, date or number functions.
The basic syntax is as follows:
Example:
Consider a table “CUSTOMERS”_BKP with similar structure as “CUSTOMERS” table.
Now to copy complete “CUSTOMERS” table into “CUSTOMERS”_BKP, following is thesyntax:
I.3. Subqueries with the UPDATE Statement: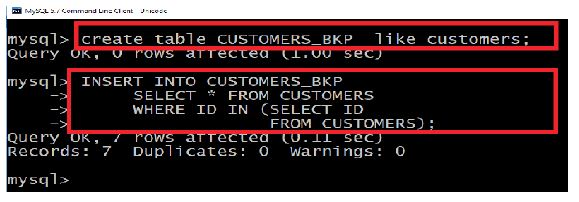
The subquery can be used in conjunction with the UPDATE statement. Either single
or multiple columns in a table can be updated when using a subquery with theUPDATE statement.
The basic syntax is as follows:
Example:
Assuming, we have “CUSTOMERS”_BKP table available which is backup of
“CUSTOMERS” table.
Following example updates SALARY by 0.25 times in “CUSTOMERS” table for all the“Customers” whose AGE is greater than or equal to 27:
I.4. Subqueries with the DELETE Statement: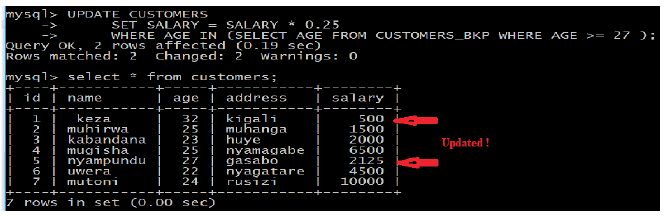
The subquery can be used in conjunction with the DELETE statement like with anyother statements mentioned above.
The basic syntax is as follows:
Example:
Assuming, we have “CUSTOMERS”_BKP table available which is backup of
“CUSTOMERS” table.
Following example deletes records from “CUSTOMERS” table for all the “Customers”whose AGE is greater than or equal to 27:
delete
The SQL DELETE Query is used to delete the existing records from a table.
You can use WHERE clause with DELETE query to delete selected rows, otherwise all
the records would be deleted.The basic syntax of DELETE query with WHERE clause is as follows:

Following is an example, which would DELETE a customer, whose ID is 6:
If you want to DELETE all the records from “CUSTOMERS” table, you do not need to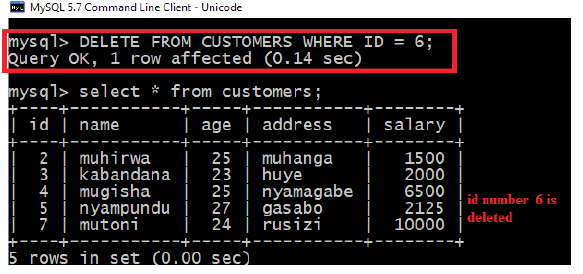
use WHERE clause and DELETE query would be as follows:
4.2.3 Data Control Language (DCL)
SQL GRANT and REVOKE commands
DCL commands are used to enforce database security in a multiple user database
environment. Two types of DCL commands are GRANT and REVOKE. Only Database
Administrator’s or owners of the database object can provide/remove privileges ona database object.
a. SQL GRANT Command
SQL GRANT is a command used to provide access or privileges on the database
objects to the users.The Syntax for the GRANT command is:
* privilege_name is the access right or privilege granted to the user. Some of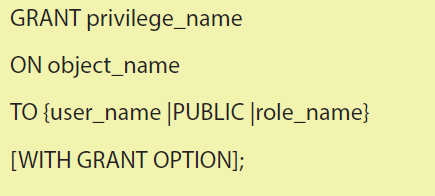
the access rights are ALL, EXECUTE, and SELECT.
* object_name is the name of an database object like TABLE, VIEW, STORED
PROC and SEQUENCE.
* user_name is the name of the user to whom an access right is being granted.
* Public is used to grant access rights to all users.
* Roles are a set of privileges grouped together.
* With grant option - allows a user to grant access rights to other users.
For Example:
GRANT SELECT ON employee TO user1; This command grants a SELECT permission
on employee table to user1.You should use the WITH GRANT option carefully
because for example if you GRANT SELECT privilege on employee table to user1
using the WITH GRANT option, then user1 can GRANT SELECT privilege on employee
table to another user, such as user2 etc. Later, if you REVOKE the SELECT privilege onemployee from user1, still user2 will have SELECT privilege on employee table.
b. SQL REVOKE Command:
The REVOKE command removes user access rights or privileges to the database
objects.The Syntax for the REVOKE command is:
For Example:
REVOKE SELECT ON employee FROM user1;This command will REVOKE a SELECT
privilege on employee table from user1.When you REVOKE SELECT privilege on a
table from a user, the user will not be able to SELECT data from that table anymore.
However, if the user has received SELECT privileges on that table from more than one
users, he/she can SELECT from that table until everyone who granted the permissionrevokes it. You cannot REVOKE privileges if they were not initially granted by you.
c. Privileges and Roles:
Privileges: Privileges defines the access rights provided to a user on a database
object. There are two types of privileges.
1. System privileges - This allows the user to CREATE, ALTER, or DROP
database objects.
2. Object privileges - This allows the user to EXECUTE, SELECT, INSERT,
UPDATE, or DELETE data from database objects to which the privilegesapply.
Application activity 4.9:
You are given a flat database named “Library”, with a relation Book (ISBN (Text,
primary key), title (text), author (text), pages (integer), and price (integer)).
i. Create student and teacher users
ii. Give student user “selection” abilities only
iii. Give all rights to user teacheriv. Revoke selection rights to students
Application activity 4.10:
XYZ Ltd is a company that focusses on finding ICT and technology related
solution to the citizens of Rwanda. It develops software and offers maintenance.
It has many competitors in Rwanda and in East Africa, but XYZ Ltd tries to be a
market winner in the region. One day, unknown person managed to have access
and enter to the XYZ Ltd systems without company’s authorization. That person
managed to change the passwords that the company used in its everyday
activities.
1. Discuss the challenges that the company should face
2. Can granting privileges help in preventing such cases? If yes, showhow. If no, explain
4.3.Database security concept
As computers need to be physically and logically protected, the database inside
needs also to be secured. There are some principles linked to databases so that
they can remain meaningful. Those principles are integrity, Availability, Privacy and
Confidentiality.
When dealing with a database belonging to an individual or an organization
(company), Some actions are done to Backup and Concurrent control for the sakeof security.
Activity 4.10:
1. What are the problems that a database can face in a computer?
2. How the security of database can be done?
3. Who is responsible of the security of a database?
4. What are the consequences that can happen when database security is
violated?
5. Discuss security measure that can be taken to keep database secure.Data integrity refers to the overall completeness, accuracy and consistency of data.
4.3.1. Integrity
There are four types of integrity:
»»Entity (or table) integrity requires that all rows in a table have a unique identifier,
known as the primary key value. Whether the primary key value can be changed,
or whether the whole row can be deleted, depends on the level of integrity
required between the primary key and any other tables.
»»Referential integrity ensures that the relationship between the primary key (in a
referenced table) and the foreign key (in each of the referencing tables) is always
maintained. The maintenance of this relationship means that:
i. A row in a referenced table cannot be deleted, nor can the primary key be
changed, if a foreign key refers to the row. For example, you cannot delete
a customer that has placed one or more orders.
ii. A row cannot be added to a referencing table if the foreign key does not
match the primary key of an existing row in the referenced table. For
example, you cannot create an order for a customer that does not exist.
»»Domain (or column) integrity specifies the set of data values that are valid for
a column and determines whether null values are allowed. Domain integrity is
enforced by validity checking and by restricting the data type, format, or range of
possible values allowed in a column.
»»User-Defined integrity: Enforces some specific business rules that do not fall into
entity, domain, or referential integrity.
4.3.2. Availability
Availability is the condition where in a given resource can be accessed by its
consumers. So in terms of databases, availability means that if a database is available,
the users of its data; that is, applications, “Customers”, and business users; can access
it. Any condition that renders the resource inaccessible causes the opposite of
availability: unavailability.
Another perspective on defining availability is the percentage of time that a system
can be used for productive work. The required availability of an application will vary
from organization to organization, within an organization from system to system,and even from user to user.
Database availability and database performance are terms that are often confused
with one another, and indeed, there are similarities between the two. The major
difference lies in the user’s ability to access the database. It is possible to access a
database suffering from poor performance, but it is not possible to access a database
that is unavailable. So, when does poor performance turn into unavailability?
If performance suffers to such a great degree that the users of the database cannot
perform their job, the database has become, for all intents and purposes, unavailable.
Nonetheless, keep in mind that availability and performance are different and must
be treated by the database administrator as separate issues; even though a severe
performance problem is a potential availability problem.
Availability comprises four distinct components, which, in combination, assure that
systems are running and business can be conducted:
Manageability: the ability to create and maintain an effective environment that
delivers service to users
Recoverability: the ability to reestablish service in the event of an error or
component failure
Reliability: the ability to deliver service at specified levels for a stated period
Serviceability: the ability to determine the existence of problems, diagnose their
cause(s), and repair the problems.
All four of these “abilities” impact the overall availability of a system, database, or
application.
4.3.3. Data Privacy
Privacy of information is extremely important in this digital age where everything is
interconnected and can be accessed and used easily. The possibilities of our private
information being extremely vulnerable are very real, which is why we require data
privacy. We can describe the concept as:
Data privacy, also known as information privacy, is the necessity to preserve and
protect any personal information, collected by any organization, from being accessed
by a third party. It is a part of Information Technology that helps an individual or an
organization determine what data within a system can be shared with others andwhich should be restricted.
What Type of data is included?
Any personal data that could be sensitive or can be used maliciously by someone
is included when considering data privacy. These data types include the following:
• Online Privacy: This includes all personal data that is given out during
online interactions. Most sites have a privacy policy regarding the use of
the data shared by users or collected from users.
• Financial Privacy: Any financial information shared online or offline is
sensitive as it can be utilized to commit fraud.
• Medical Privacy: Any details of medical treatment and history is privileged
information and cannot be disclosed to a third party. There are very
stringent laws regarding sharing of medical records.
• Residential and geographic records: sharing of address online can be a
potential risk and needs protection from unauthorized access.
• Political Privacy: this has become a growing concern that political
preferences should be privileged information.
• Problems with providing Data Security
• It is not an easy task to provide data security. Most organizations have
problems in providing proper information privacy. These problems
include:
• Difficulty in understanding and defining what is sensitive data and what
is not.
• With data growing in volume by the day, most organizations struggle
to create real-time masking facilities and security policies to efficiently
protect all the data.
• Difficulty to screen and review data from a central location with outmoded
tools and bloated databases.
Importance of Data Security
* Data security is extremely important for any individual or organization, as
theft of data, can cause huge monetary losses. Data security can help an
organization by:
• Preventing theft of data;
• Preserving data integrity;
• Containing a cost of compliance to data security requirements;• Protection of privacy.
Legal provisions for Data Security
The laws that govern data security vary across the world. Different countries and legal
systems deal with it in their way. But most laws agree that personal data is shared
and processed only for the purpose for which the information has been collected.
In Rwanda we have RURA (Rwanda Utilities Regulatory Agency) that govern datasecurity issues.
4.3.4. Confidentiality
Confidentiality refers to protecting information from being accessed by unauthorized
parties. In other words, only the people who are authorized to do so can gain access
to sensitive data. Imagine your bank records. You should be able to access them, of
course, and employees at the bank who are helping you with a transaction should
be able to access them, but no one else should.
A failure to maintain confidentiality means that someone who shouldn’t have access
has managed to get it, through intentional behavior or by accident. Such a failure of
confidentiality, commonly known as a breach, typically cannot be remedied. Once
the secret has been revealed, there’s no way to un-reveal it.
If your bank records are posted on a public website, everyone can know your bank
account number, balance, etc., and that information can’t be erased from their
minds, papers, computers, and other places. Nearly all the major security incidentsreported in the media today involve major losses of confidentiality.
a. Backup
In information technology, a backup, or the process of backing up, refers to the
copying and archiving of computer data so it may be used to restore the original
after a data loss event.
A catastrophic failure is one where a stable, secondary storage device gets corrupt.
With the storage device, all the valuable data that is stored inside is lost. We have
two different strategies to recover data from such a catastrophic failure:
* Remote backup – Here a backup copy of the database is stored at a remote
location from where it can be restored in case of a catastrophe.* Alternatively, database backups can be taken on magnetic tapes and storedSo, all that we need to do here is to take a backup of all the logs at frequent intervals
at a safer place. This backup can later be transferred onto a freshly installed
database to bring it to the point of backup. Grown-up databases are too
bulky to be frequently backed up. In such cases, we have techniques where
we can restore a database just by looking at its logs.
of time. The database can be backed up once a week, and the logs being very small
can be backed up every day or as frequently as possible.
b. Remote access
Individuals, small and big institutions/companies are using databases in their daily
businesses. Most of the time institutions have agencies spread around the country,
region or the world. Umwalimu SACCO is a saving and credit Cooperative that
helps teachers to improve their lives by getting financial loans at low interests. This
institution is having different agencies in different districts. The central agency is
located at Kigali and host the main database of all members of Umwalimu SACCO
in Rwanda. When a client goes to look for a service at an agency, the teller requests
permissions from Kigali by identifying, authenticating him/her self so that the
authorization can be granted to him/her. The whole network works in the mode of
Cleint/Server. The fact of getting connection to the server from far is what we call
“Remote Access”. Hence, the database is accessed remotely. This act requires some
security measures because otherwise anybody can disturbs the system of working
and hack the whole business system of Umwalimu SACCO.
This institution needs then to set rules and regulations to manage the remote access
to its information.
c. Concurrent control
Process of managing simultaneous operations on the database without having
them interfere with one another.
- Prevents interference when two or more users are accessing database
simultaneously and at least one is updating data.
- Although two transactions may be correct in themselves, interleaving ofoperations may produce an incorrect result.
Three examples of potential problems caused by concurrency:
• Lost update problem.
• Uncommitted dependency problem.
• Inconsistent analysis problem.
Application activity 4.11:
1. Discuss the advantages of data backup.
2. Explain the advantages of remote access to big companies.
3. Discuss the reasons why a database administrator must understand
well the concept of privacy as used in database.
4. Compare the concepts of integrity, availability and confidentiality.
Discuss what should happen when they are violated (case by case).
5. A secondary school has a Management Information System hosted on
their own server located inside their compound. All the important data
related to students, teachers, salaries, marks, library, etc. are in that
server.
One day, it happened that the Head Master finds that some students have the
lists of their marks in all courses before deliberation. He investigated and found
that the students did not get marks from any teachers or administrative/technical
staff of the school.
• In groups, discuss what should happened in the server of the school
• Is data privacy assured in that server?
• What are the measures that the school has to put in place to protect
their data.
4.3.5. Database threats
Activity 4.11
i. From what you have seen in computer security, what are the possible
threats of computers?
ii. What do you do in case you realize that there are threats for your
computer system?iii. Can database be attacked by hackers?
Threat is any situation or event, whether intentional or unintentional, that will
adversely affect a system and consequently an organization.
Threats to databases result in the loss or degradation of some or all of the followingsecurity goals: integrity, availability, and confidentiality.
• Loss of integrity: Database integrity refers to the requirement that
information be protected from improper modification. Modification of
data includes creation, insertion, modification, changing the status of
data, and deletion. Integrity is lost if unauthorized changes are made to
the data by either intentional or accidental acts. If the loss of system or
data integrity is not corrected, continued use of the contaminated system
or corrupted data could result in inaccuracy, fraud, or erroneous decisions.
• Loss of availability: Database availability refers to making objects
available to a human user or a program to which they have a legitimate
right.
• Loss of confidentiality: Database confidentiality refers to the protection
of data from unauthorized disclosure. The impact of unauthorized
disclosure of confidential information can range from violation of the
Data Privacy Act to the jeopardization of national security. Unauthorized,
unanticipated, or unintentional disclosure could result in loss of public
confidence, embarrassment, or legal action against the organization.
In other words we can say that database threats can appear in form of unauthorizedusers, physical damage, and Data corruption.
a. Database protectionThe protection of a database can be done through access control and data encryption
Access control
- Based on the granting and revoking of privileges.
- A privilege allows a user to create or access (that is read, write, or modify)
some database object (such as a relation, view, and index) or to run certain
DBMS utilities.
- Privileges are granted to users to accomplish the tasks required for theirjobs.
Data encryption
- The encoding of the data by a special algorithm that renders the data
- unreadable by any program without the decryption key.
Application activity 4.12:
You are tasked to design a database of your school. Discuss the steps you will
follow to come up with genuine product by keeping in mind the data securityand the protection of the database against the potential threats.
4.3.6. Database planning and designing
Activity 4.12
1. Discuss the pillars of database design
2. Why is database planning necessary?
3. Discuss activities involved in database planning.
Before planning, designing and managing a database, first it is created. Its creation
goes through defined steps known as Database System Development Lifecycle.Those steps are:
• Database planning
• System definition
• Requirements collection and analysis
• Database design
• DBMS selection (optional)
• Prototyping (optional)
• Implementation
• Data conversion and loading
• Testing• Operational maintenance
A. Database Planning
Management activities that allow stages of database system development
lifecycle to be realized as efficiently and effectively as possible.
◊ Must be integrated with overall information system strategy of the
organization.
◊ Database planning should also include development of standards that
govern:
• How data will be collected,
• How the format should be specified,
• What necessary documentation will be needed,
• How design and implementation should proceed.
Database Planning – Mission Statement:
• Mission statement for the database project defines major aims of database
application.
• Those driving database project normally define the mission statement.
• Mission statement helps clarify purpose of the database project and
provides clearer path towards the efficient and effective creation of
required database system.
Database Planning – Mission Objectives:
• Once mission statement is defined, mission objectives are defined.
• Each objective should identify a particular task that the database must
support.
• May be accompanied by some additional information that specifies the
work to be done, the resources with which to do it, and the money to payfor it all.
System Definition
• Database application may have one or more user views.
• Identifying user views helps ensure that no major users of the database
are forgotten when developing requirements for new system.
• User views also help in development of complex database system allowing
requirements to be broken down into manageable pieces.
Requirements Collection and Analysis
• Process of collecting and analysing information about the part of
organization to be supported by the database system, and using this
information to identify users’ requirements of new system.
• Information is gathered for each major user view including:
* a description of data used or generated;
* details of how data is to be used/generated;
* any additional requirements for new database system.
* Information is analyzed to identify requirements to be included in newdatabase system. Described in the requirements specification.
• Another important activity is deciding how to manage the requirementsfor a database system with multiple user views.
Three main approaches:
• centralized approach;
• view integration approach;
• combination of both approaches(hybrid).
Centralized approach
• Requirements for each user view are merged into a single set of
requirements.
• A data model is created representing all user views during the databasedesign stage.
View integration approach
* Requirements for each user view remain as separate lists.
* Data models representing each user view are created and then merged
later during the database design stage.
◊ Data model representing single user view (or a subset of all user views) is
called a local data model.
◊ Each model includes diagrams and documentation describing requirements
for one or more but not all user views of database.
◊ Local data models are then merged at a later stage during database design
to produce a global data model, which represents all user views for thedatabase.
B. Database Design
In every institution, there is a process of creating a design for a database that will
support the enterprise’s mission statement and mission objectives for the required
database system.
The main approaches include:
◊ Top-down or Entity-Relationship Modelling◊ Bottom-up or Normalisation
Top-down approach
* Starts with high-level entities and relationships with successive
refinement to identify more detailed data model.* Suitable for complex databases.
Bottom-up approach
* Starts with a finite set of attributes and follows a set of rules to group
attributes into relations that represent entities and relationships.* Suitable for small number of attributes.
The main purposes of data modeling include:
* to assist in understanding the meaning (semantics) of the data;
* to facilitate communication about the information requirements.
* Building data model requires answering questions about entities,relationships, and attributes.
There are three phases of database design: Conceptual database design, Logical
database design and Physical database design.
Conceptual Database Design:
* Process of constructing a model of the data used in an enterprise,
independent of all physical considerations.
* Data model is built using the information in users’ requirements
specification.
* Conceptual data model is source of information for logical design phase.
Logical Database Design:
* Process of constructing a model of the data used in an enterprise based
on a specific data model (e.g. relational), but independent of a particular
DBMS and other physical considerations.
* Conceptual data model is refined and mapped on to a physical data
model.
Physical Database Design:
* Process of producing a description of the database implementation on
secondary storage.
* Describes base relations, file organizations, and indexes used to achieve
efficient access to data. Also describes any associated integrity constraints
and security measures.* Tailored to a specific DBMS.
DBMS Selection:
The selection of an appropriate DBMS to support the database system follows these
steps: define Terms of Reference of study; shortlist two or three products; evaluateproducts and Recommend selection and produce report.
END UNIT ASSESSMENT
Part I: Relational algebra and SQL statements
1. 1. A company organizes its activities in projects. Products that are used in
the projects are bought from suppliers. This is described in a database with
the following schema: Projects(projNbr, name, city) Products(prodNbr,
name, color) Suppliers(supplNbr, name, city) Deliveries(supplNbr, prodNbr,
projNbr, number). Write relational algebra expressions that give the
following information:
a. All information about all projects.
b. All information about all projects in Kigali.
c. The supplier numbers of the suppliers that deliver to project number 123.
d. The product numbers of products that are delivered by suppliers in Kigali.
e. All pairs of product numbers such that at least one supplier delivers
both products.
4. The following relations keep track of airline flight information:
Flights(flno: integer, from: string, to: string, distance: integer, departs: time,
arrives: time, price: real) Aircraft(aid: integer, aname: string, cruisingrange: integer)
Certified(eid: integer, aid: integer) Employees(eid: integer, ename: string, salary:
integer)
Note that the Employees relation describes pilots and other kinds of employees as
well; every pilot is certified for some aircraft, and only pilots are certified to fly. Write
each of the following queries in SQL.
i. Find the names of aircraft such that all pilots certified to operate them have
salaries more than $80,000.
ii. For each pilot who is certified for more than three aircraft, find the eid and
the maximum cruising range of the aircraft for which she or he is certified.
iii. Find the names of pilots whose salary is less than the price of the cheapest
route from Kigali to New York.
iv. For all aircraft with cruising range over 1000 miles, find the name of the
aircraft and the average salary of all pilots certified for this aircraft.
v. Find the names of pilots certified for some Boeing aircraft.
vi. Find the aids of all aircraft that can be used on routes from Kigali to London.
vii. Identify the routes that can be piloted by every pilot who makes more than
$100,000.
viii. Print the names of pilots who can operate planes with cruising range
greater than 3000 Km but are not certified on any Boeing aircraft.
ix. A customer wants to travel from Kigali to New York with no more than
two changes of flight. List the choice of departure times from Kigali if the
customer wants to arrive in New York by 6 p.m.
x. Compute the difference between the average salary of a pilot and the
average salary of all employees (including pilots).
xi. Print the name and salary of every non pilot whose salary is more than the
average salary for pilots.
xii. Print the names of employees who are certified only on aircrafts with
cruising range longer than 1000 Km.
xiii. Print the names of employees who are certified only on aircrafts with
cruising range longer than 1000 Km, but on at least two such aircrafts.
xiv. Print the names of employees who are certified only on aircrafts with
cruising range longer than 1000 Km and who are certified on some Boeingaircraft.
Part II: Database projects
1. Consider the following relations:
Student (snum: integer, sname: string, major: string, level: string, age: integer)
Class (name: string, meets at: string, room: string, fid: integer)
Enrolled (snum: integer, cname: string)
Faculty (fid: integer, fname: string, deptid: integer)
The meaning of these relations is straightforward; for example, Enrolled has one
record per student-class pair such that the student is enrolled in the class. Level is a
two character code with 4 different values (example: Junior: A Level etc)
Write the following queries in SQL. No duplicates should be printed in any of the
answers.
i. Find the names of all Juniors (level = A Level) who are enrolled in a class
taught by Prof. Kwizera
ii. ii. Find the names of all classes that either meet in room R128 or have five or
more Students enrolled.
iii. Find the names of all students who are enrolled in two classes that meet at
the same time.
iv. Find the names of faculty members who teach in every room in which some
class is taught.
v. Find the names of faculty members for whom the combined enrollment ofthe courses that they teach is less than five.
2. The following relations keep track of airline flight information:
Flights (no: integer, from: string, to: string, distance: integer, Departs: time, arrives:
time, price: real) Aircraft (aid: integer, aname: string, cruisingrange: integer)
Certified (eid: integer, aid: integer)
Employees (eid: integer, ename: string, salary: integer)
Note that the Employees relation describes pilots and other kinds of employees as
well; every pilot is certified for some aircraft, and only pilots are certified to fly.
Write each of the following queries in SQL:
i. Find the names of aircraft such that all pilots certified to operate them have
salaries more than Rwf.80, 000.
ii. For each pilot who is certified for more than three aircrafts, find the eid and
the maximum cruisingrange of the aircraft for which she or he is certified.
iii. Find the names of pilots whose salary is less than the price of the cheapest
route from Kigali to Nairobi.
iv. For all aircraft with cruisingrange over 1000 Kms,. Find the name of the
aircraft and the average salary of all pilots certified for this aircraft.
v. Find the names of pilots certified for some Boeing aircraft.
vi. Find the aids of all aircraft that can be used on routes from Rusizi to Kigali.
3. Consider the following database of student enrollment incourses & books adopted for each course.
STUDENT (regno: string, name: string, major: string, bdate:date)
COURSE (course #:int, cname:string, dept:string)
ENROLL ( regno:string, course#:int, sem:int, marks:int)
BOOK _ ADOPTION (course# :int, sem:int, book-ISBN:int)
TEXT (book-ISBN:int, book-title:string, publisher:string, author:string)
i. Create the above tables by properly specifying the primary keys and the
foreign keys.
ii. Enter at least five records for each relation.
iii. Demonstrate how you add a new text book to the database and make this
book be adopted by some department.
iv. Produce a list of text books (include Course #, Book-ISBN, Book-title) in the
alphabetical order for courses offered by the ‘CS’ department that use more
than two books.
v. List any department that has all its adopted books published by a specific
publisher.
vi. Generate suitable reports.vii. Create suitable front end for querying and displaying the results.
4. The following tables are maintained by a book dealer.
AUTHOR (author-id:int, name:string, city:string, country:string)
PUBLISHER (publisher-id:int, name:string, city:string, country:string)
CATALOG (book-id:int, title:string, author-id:int, publisher-id:int, category-id:int,
year:int, price:int)
CATEGORY (category-id:int, description:string)
ORDER-DETAILS (order-no:int, book-id:int, quantity:int)
i. Create the above tables by properly specifying the primary keys and the
foreign keys.
ii. Enter at least five records for each relation.
iii. Give the details of the authors who have 2 or more books in the catalog and
the price of the books is greater than the average price of the books in the
catalog and the year of publication is after 2000.
iv. Find the author of the book which has maximum sales.
v. Demonstrate how you increase the price of books published by a specific
publisher by 10%.
vi. Generate suitable reports.vii. Create suitable front end for querying and displaying the results.
5. Consider the following database for a banking enterprise
BRANCH(branch-name:string, branch-city:string, assets:real)
ACCOUNT(accno:int, branch-name:string, balance:real)
DEPOSITOR(customer-name:string, accno:int)
CUSTOMER(customer-name:string, customer-street:string, customer-city:string)
LOAN(loan-number:int, branch-name:string, amount:real)
BORROWER(customer-name:string, loan-number:int)
i. Create the above tables by properly specifying the primary keys and the
foreign keys
ii. Enter at least five records for each relation
iii. Find all the “Customers” who have at least two accounts at the Main branch.
iv. Find all the “Customers” who have an account at all the branches located in
a specific city.
v. Demonstrate how you delete all account records at every branch located
in a specific city.
vi. Generate suitable reports.
vii. Create suitable front end for querying and displaying the results.
6. XYZ high school’s database has the following information:
i. Professors have an SSN, a name, an age, a rank, and a research specialty.
Projects have a project number, a sponsor name (e.g., USAID), a starting
date, an ending date, and a budget.
ii. Graduate students have an SSN, a name, an age, and a degree program
(e.g., Bachelor’s or Masters..).
iii. Each project is managed by one professor (known as the project’s principal
investigator).
iv. Each project is worked on by one or more professors (known as the project’s
co-investigators).
v. Professors can manage and/or work on multiple projects.
vi. Each project is worked on by one or more graduate students (known as the
project’s research assistants).
vii. When graduate students work on a project, a professor must supervise their
work on the project.
viii. Graduate students can work on multiple projects, in which case they
will have a (potentially different) supervisor for each one.
ix. Departments have a department number, a department name, and a main
office.
x. Departments have a professor (known as the chairman) who runs the
department.
xi. Professors work in one or more departments, and for each department that
they work in, a time percentage is associated with their job.
Graduate students have one major department in which they are working on their
degree. Each graduate student has another, more senior graduate student (known
as a student advisor) who advises him or her on what courses to take.
i. Design and draw an ERD that captures the information about the XYZ High
school. Use only the basic ER model here; that is, entities, relationships, and
attributes. Be sure to indicate any key and participation constraints.
ii. Use SQL statement to computerize the above ERD.
iii. Use your favorite programming language and design front end to interactwith your back end (database).
Part III: Database security
1. Explain the following terms as to database security:
i. Threat
ii. Availability
iii. Confidentiality
iv. Privacy
v. Integrity
2. Discuss the role of backup in database field.
3. In your school, find and explain the possible security issues that can harm
your database.
4. Database security is a big concern. Discuss the measures you can adopt tokeep your database secure.