General
- Biology SME Y3 SB File Uploaded 1/11/21, 16:56
UNIT 4: PRINCIPLES OF GENE TECHNOLOGY AND ITS APPLICATIONS
Key unit competence
Explain the principles of gene technology and evaluate how gene technology
is applied in areas of medicine, forensic science and agricultureIntroductory activity 4
You hear about them all the time. They are often depicted in cartoons, comic
books, movies, and science fiction as mad scientists. These are the scientists
who take a gene from one organism and place it into an unrelated organism.
These are the scientists who make hormones that farmers inject into the cows
that produce the milk we drink.These are the scientists who modify the crops we eat, creating what some
people call “Franken foods” or genetically modified organisms. The figure
below shows a GMO tomato and a GMO rice also called golden rice.
You may have wondered if it might soon be possible to replace a beloved
family member or pet, or bring back extinct species through cloning, or even
clone yourself. You might worry about a future where parents unwilling to fix
their children’s “genetic defects” face discrimination.Use the image above and your own knowledge to answer the questions
that follow:
a) Who are these scientists who make such manipulations?
b) What do they do?
c) What are the basic tools that these scientists use?
d) What are the possible products that they do?
e) Is anyone trying to determine if it is unhealthy to eat these modified
foods, whether genetically modified plants will cause environmental
problems, or if genetically modified animals are less healthy than their
counterparts?4.1 Recombinant DNA technology
Activity 4.1
arpenters require tools such as hammers, screwdrivers, and saws; surgeons
require scalpels, forceps, and stitching needles; and mechanics require hoists,
wrenches, and pumps. These individuals use their implements to modify,
deconstruct, or build a system that they are working with. Just like any other
technicians, molecular biologists use tools to complete a project. The tools
in their laboratories may aid them in investigating genetic disorders, altering
the genetic makeup of organisms so that they produce useful products such
as insulin, or analysing DNA evidence in a criminal investigation. Find out the
possible tools used in recombinant DNA technology and their functions.Genetic engineering, also known as recombinant DNA (rDNA) technology,
means altering the genes in a living organism to produce a Genetically Modified
Organism (GMO) with a new genotype. Various kinds of genetic modification
are possible: inserting a foreign gene from one species into another, forming a
transgenic organism; altering an existing gene so that its product is changed; or
changing gene expression so that it is translated more often or not at all.4.1.1 Techniques of genetic engineering
Genetic engineering is a very young discipline, and is only possible due to
the development of techniques from the 1960s onwards. These techniques
have been made possible from our greater understanding of DNA and how it
functions following the discovery of its structure by Watson and Crick in 1953.
Although the final goal of genetic engineering is usually the expression of a genein a host, in fact most of the techniques and time in genetic engineering are
spent isolating a gene and then cloning it.An overview of gene transfer
There are many different ways in which a GMO may be produced, but these
steps are essential.
• The gene that is required is identified. It may be cut from a chromosome,
made from mRNA by reverse transcription or synthesized from nucleotides.
• Multiple copies of the gene are made using the technique known as the
polymerase chain reaction (PCR).
• The gene is inserted into a vector which delivers the gene to the cells of
the organism. Examples of vectors are plasmids, viruses and liposomes.
• The vector takes the gene into the cells.
• The cells that have the new gene are identified and cloned.To perform these steps, the genetic engineer needs a ‘tool kit’ consisting of:
• Enzymes, such as restriction endonucleases, DNA ligase and
reverse transcriptase
• Vectors, including plasmids and viruses
• Host cell, a living system (microbial, plant, animal) in which the vector can
be propagated.
• Genes coding for easily identifiable substances that can be used as
markers.
4.1.2 Plasmids
A plasmid is a genetic structure, in some cells, that can replicate independently
of the chromosomes; it is typically a small circular DNA strand in the cytoplasm
of a bacterium or protozoan. Plasmids are much used in the laboratory during
manipulation of genes as vectors.The properties of plasmids are:
– It is big enough to hold the desired gene.
– It is circular (or more accurately a closed loop), so that it is less likely
to be broken down.
– It contains control sequences, such as a transcription promoter, so that
the gene will be replicated or expressed.
– It contains marker genes, so that cells containing the vector can be
identified.Plasmids are not the only type of vector that can be used. Viruses can also
be used as vectors. Another group of vectors are liposomes, which are tiny
spheres of lipid containing the DNA.The production of genetically modified organisms (GMO), also called transgenic
organisms, is a multistage process which can be generally summarized as
follows:
– Identification of the gene of interest.
– Isolation of the gene of interest.
– Cutting of gene of interest and opening of plasmid with restriction
enzymes in order to have sticky ends.
– Associating the gene with an appropriate promoter and poly -A
sequence and insertion into plasmids.
– Multiplying the plasmid in bacteria and recovering the cloned construct
for injection.
– Transference of the construct into the recipient tissue, usually fertilized
eggs.
– Integration of gene into recipient genome.
– Expression of gene in recipient genome.
– Inheritance of gene through further generations.Application activity 4.1
1) Explain briefly the terms below:
a) Recombinant DNA
b) Transgenic organism
c) Enzyme
2) State the main tools of a genetic engineer and their functions.4.2 Roles of enzymes in genetic engineering
Activity 4.2
Enzymes are biological molecules which speed up the rates of chemical
reactions in our body. There are different enzymes with different functions
used in genetic engineering. Find the information about these enzymes and
their possible functions.The enzymes involved in gene manipulation include; restriction endonucleases
(restriction enzymes), methylases, ligase and reverse transcriptase.4.2.1 Restriction enzymes
These are enzymes that cut DNA at specific sites. They are properly called
restriction endonucleases because they cut the bonds in the middle of the
polynucleotide chain. Each type of restriction enzyme recognizes a characteristic
sequence of nucleotides that is known as its recognition site. A recognition
site is a specific sequence within double-stranded DNA, usually palindromic
and consisting of four to eight nucleotides, that a restriction endonuclease
recognizes and cleaves. Molecular biologists can use these enzymes to cut
DNA in a predictable and precise manner.Most restriction enzymes make a staggered cut in the two strands, forming
sticky ends.The cut ends are “sticky” because they have short stretches of single-stranded
DNA. These sticky ends will stick (or anneal) to another piece of DNA by
complementary base pairing, but only if they have both been cut with the same
restriction enzyme. Restriction enzymes are highly specific, and will only cut
DNA at specific base sequences, 4-8 base pairs long.Restriction enzymes are produced naturally by bacteria as a defense against
viruses (they “restrict” viral growth), but they are enormously useful in genetic
engineering for cutting DNA at precise places (“molecular scissors”).
Short lengths of DNA cut out by restriction enzymes are called restriction
fragments. There are thousands of different restriction enzymes known, with
over a hundred different recognition sequences. Restriction enzymes are named
after the bacteria species they came from, so Eco R1 is from E. coli strain R.Table 4.1: List of some restriction enzymes and their respective recognition sites
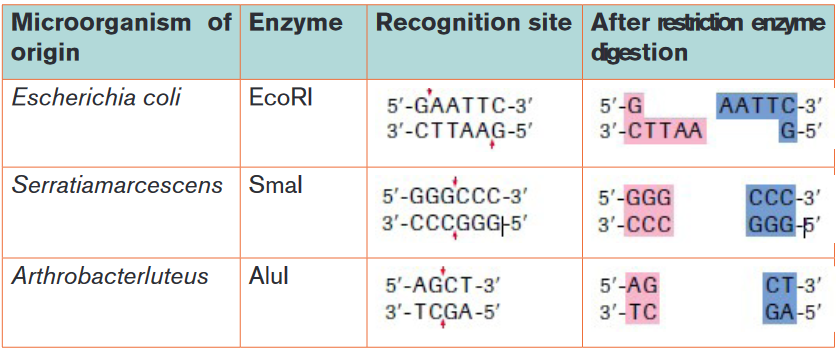
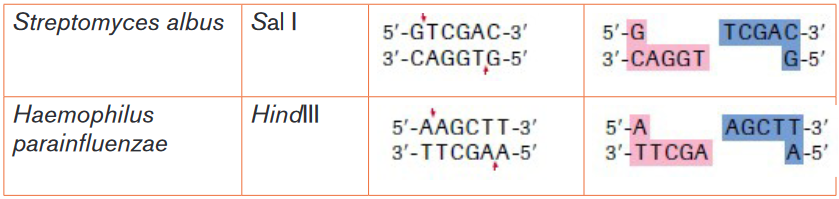
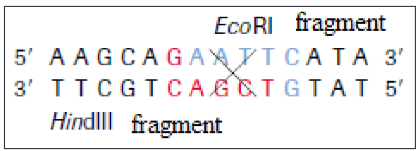
The ends of DNA fragments produced from a cut by different restriction
endonucleases differ, depending on where the phosphodiester bonds are
broken in the recognition site. In the example in Table 4.1, EcoRI produces
sticky ends; that is, both fragments have DNA nucleotides that are now
lacking their respective complementary bases. These overhangs are produced
because EcoRI cleaves between the guanine and the adenine nucleotide on
each strand. Since A and G are at opposite ends of the recognition site on each
of the complementary strands, the result is the overhang. Another restriction
endonuclease, SmaI, produces blunt ends, which means that the ends of the
DNA molecule fragments are fully base paired (Table 4.1).Sticky ends are fragment end of a DNA molecule with short single stranded
overhangs, resulting from cleavage by a restriction enzyme. Blunt ends are
fragment ends of a DNA molecule that are fully base paired, resulting from
cleavage by a restriction enzyme.Restriction enzymes are named according to the bacteria from which they
originate.For example, the restriction enzyme BamHI is named as follows:
– B represents the genus Bacillus
– am represents the species amyloliquefaciens
– H represents the strain
– I mean that it was the first endonuclease isolated from this strain
– Following the same pattern, the rationale for the name of the restriction
enzyme Hind II is the following:
– H represents the genus Haemophilus
– in represents the species influenzae
– d represents the strain Rd
– II means that it was the second endonuclease isolated from this strain.Generally speaking, the first letter is the initial of the genus name of the organism
from which the enzyme is isolated. The second and third letters are usually the
initial letters of the species name. The fourth letter indicates the strain, while
the numerals indicate the order of discovery of that particular enzyme from that
strain of bacteria.4.2.2 Methylases
Restriction endonucleases must be able to distinguish between foreign DNA
and the genetic material of their own cells; otherwise a bacterium’s DNA would
be in danger of being cleaved by its own immune system. Methylases are
enzymes that add a methyl group to one of the nucleotides found in a restriction
endonuclease recognition site, altering its chemical composition. In prokaryotes,
they modify the recognition site ofa respective restriction endonuclease by placing
a methyl group on one of the bases, preventing the restriction endonuclease
from cutting the DNA into fragments. When foreign DNA is introduced into the
bacterium, it is not methylated, rendering it defenceless against the bacterium’s
restriction enzymes. Methylases are important tools for a molecular biologist
when working with prokaryotic organisms. They allow the molecular biologist to
protect a gene fragment from being cleaved in an undesired location.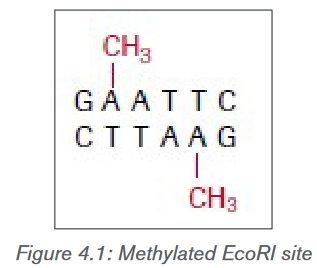
4.2.3 DNA ligase
This enzyme repairs broken DNA by joining two nucleotides in a DNA strand.
It is commonly used in genetic engineering to do the reverse of a restriction
enzyme that is to join together complementary restriction fragments. The sticky
ends allow two complementary restriction fragments to harden, but only by
weak hydrogen bonds, which can quite easily be broken by gentle heating.
The backbone is still incomplete. DNA ligase completes the DNA backbone by
forming covalent bonds. T4 DNA ligase is an enzyme that originated from the
T4 bacteriophage and which is used to join together DNA blunt or sticky ends.
So, DNA ligase is able to join complementary sticky ends produced by the same
restriction enzyme via a condensation reaction:iv) Complementary sticky ends produced by Hind III

v) Hydrogen bonds form between complementary bases. DNA ligase
reconstitutes the phosphodiester bond in DNA backbones.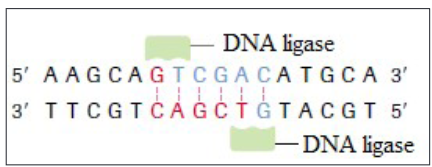
vi) If fragments are not complementary, then hydrogen bonds will not form.
4.2.4 Reverse transcriptase
Reverse transcription is a process whereby a mRNA is converted into cDNA
(complementary DNA, also called copy of DNA). It requires the enzymes called
reverse transcriptase. It is shown by this reaction:Application activity 4.2
1) Which of the following tools of recombinant DNA technology is
incorrectly paired with its use?
a) Restriction enzyme: cut DNA into smaller segments of various sizes.
b) DNA ligase: enzyme that cuts DNA, creating the sticky ends of
restriction fragments
c) DNA polymerase: used to make many copies of DNA
d) Reverse transcriptase: production of cDNA from mRNA2) The diagram below shows the stages in the insertion of the gene for
insulin into a bacterium.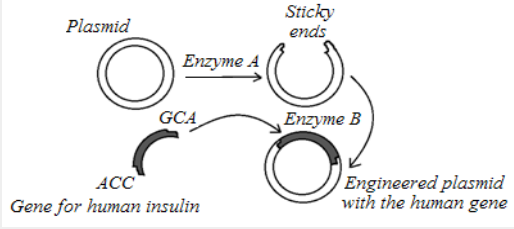
a) Name the substance that makes up the plasmid.
b) Identify the enzyme labelled A. what is its role?
c) Identify enzyme B on the diagram. What is its role?
d) What term is given to a length of DNA formed from different sources?4.3 Polymerase chain reaction (PCR)
Activity 4.3
The polymerase chain reaction is a process which can be carried out in a
laboratory to make large quantities of identical DNA from very small samples.
The process is summarized in the flowchart.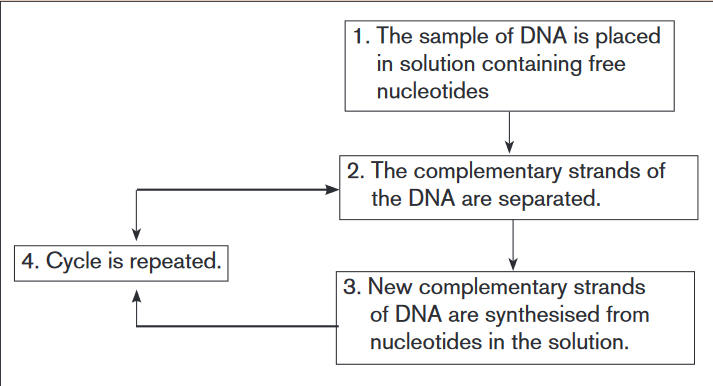
a) At the end of one cycle, two molecules of DNA have been produced
from each original molecule. How many DNA molecules will have been
produced from one molecule of DNA after 5 complete cycles?
b) Suggest one practical use to which this technique might be applied.
c) Give two ways in which the polymerase chain reaction differs from the
process of transcription.
d) The polymerase chain reaction involves semi-conservative replication.
Explain what is meant by semi-conservative replication.The Polymerase Chain reaction (PCR) is a method widely used in molecular
biology to make several copies of a specific DNA segment. Using PCR, copies
of DNA sequences are exponentially amplified to generate thousands to millions
of more copies of that particular DNA segment. DNA can clone (or amplify) DNA
samples as small as a single DNA molecule. It is a newer technique, havingbeen developed in 1983 by KARY Mullis, for which discovery he won the
Nobel Prize in 1993. The polymerase chain reaction is simply DNA replication in
a test tube. If a length of DNA is mixed with the four nucleotides (A, T, C and G)
and the enzyme DNA polymerase in a test tube, then the DNA will be replicated
many times.The polymerase chain reaction (PCR) is an automated process, making it both
rapid and efficient. It requires the following:
• The DNA fragment to be copied.
• Taq polymerase – DNA polymerase obtained from the bacterium Thermus
aquaticus, after which it is named. The bacterium lives in hot springs, and
so the remarkable feature of Taq polymerase is that it is very tolerant to
heat (it is thermostable) and does not denature at the high temperatures
of the polymerase chain reaction so that take place. DNA polymerase is
an enzyme is an enzyme capable of joining together tens of thousands of
nucleotides in a matter of minutes.
• Primers: short sequences of nucleotides that have a set of bases
complementary to those at one end of each of the two DNA fragments.
• Nucleotides: which contain each of the four bases found in DNA. They
are nucleotide triphosphate (dNTPs) as energy is required for the synthesis
of the phosphodiester bonds.
• Thermocycler: a computer-controlled machine that varies temperatures
precisely over a period of time.The polymerase chain reaction is illustrated in the figure 4.2 and is carried out
in three stages:
• Separation of the DNA double helix: the mixture containing DNA
fragments, primers, dNTPs and Taq polymerase is placed in a vessel in
the thermocycler. The temperature is increases to 95ºC causing the two
strands of the DNA fragments to separate as hydrogen bonds are broken.
• Annealing of the primers: the mixture is cooled to 55ºC causing the
primers to join (anneal) to their complementary bases at the end of
the DNA fragment. The primers provide the starting sequences for Taq
polymerase to begin DNA copying because Taq polymerase can only attach
nucleotides to the end of an existing chain. Primers also prevent the two
separate strands from simply rejoining.
• Synthesis of DNA: the temperature is increased to 72ºC. This is the
optimum temperature for the Taq polymerase to add complementary
nucleotides along each of the separated DNA strands. It begins at the
primer on both strands and adds the nucleotides in sequence until it
reaches the end of the chain.Each original DNA molecule has now been replicated to form two molecules.
The cycle is repeated from step 2 and each time the number of DNA molecules
doubles. This is why it is called a chain reaction, since the number of molecules
increases exponentially, like an explosive chain reaction. Typically, PCR is run
for 20-30 cycles. This is known as DNA amplification. The complete cycle
takes around two minutes. After only 25 cycles over a million copies of the DNA
can be made and 100 billion copies can be manufactured in just a few hours.
The PCR has revolutionized many aspects of science and medicine. Even the
minutest sample of DNA from a single hair or a speck of blood can now be
multiplied to allow forensic examination and accurate cross-matching.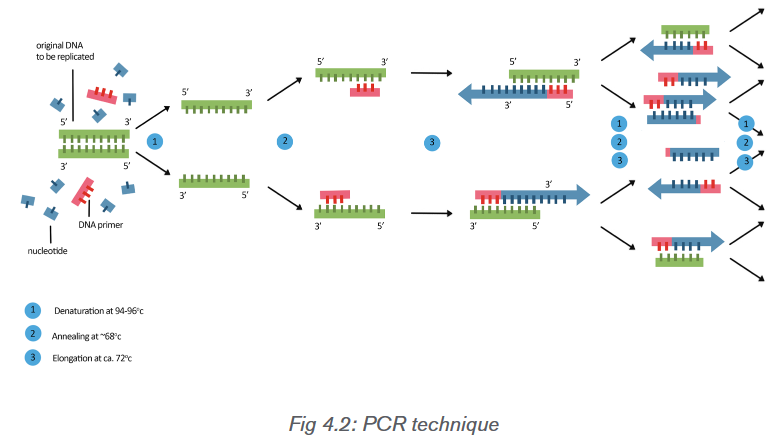
Applications of the PCR technique
PCR is useful in forensic criminal investigations, medical diagnosis, paternity
testing and genetic research, and only requires a small amount of DNA to
work. In criminal investigations, forensic scientists can find enough DNA in a
hair follicle or one cell to use as a starting point for PCR. Therefore, only a
small amount of DNA evidence is needed because it can be copied over and
over again. PCR can also improve medical diagnoses, such as confirming the
presence of the AIDS-causing virus. HIV cannot be detected immediately by
looking for antibodies, because it takes time for the body to build antibodies
against it. Traditional testing relies on the detection of these antibodies. With
PCR, primers can be designed to complement short regions of the DNA of
HIV. The DNA can be amplified and then examined for the presence of the HIV
genome. Another application of PCR is that researchers can use it to determine,
from fossil remains, whether or not two species are closely related.Application activity 4.3
1) Which of the following are required in a polymerase chain reaction?
a) DNA polymerase, template strand and primers.
b) RNA polymerase, template strand and primers
c) RNA polymerase, template strand and ligase
d) RNA polymerase, ligase and primers.
2) Each cycle of a polymerase chain reaction (PCR) takes 5 minutes. If
there are 1000 DNA molecules at the start of the reaction, how long will it
take for the number of fragments produced by the reaction to be greater than
1 million?
a) 15 minutes
b) 35 minutes
c) 50 minutes
d) 55 minutes4.4 Gel electrophoresis
Activity 4.4
Explain the process of gel electrophoresis, the process by which
electrophoresis takes place and the possible importance of this technique.Gel electrophoresis is a laboratory technique used to separate mixtures of
DNA, RNA or proteins according to molecular size. In gel electrophoresis, the
molecules to be separated are pushed by an electrical field through a gel that
contains small pores.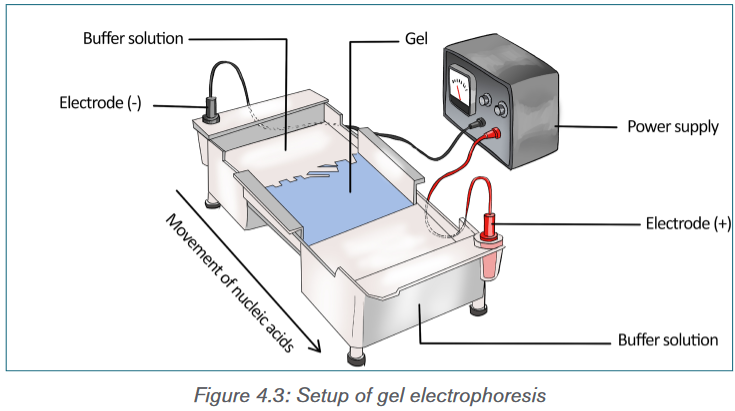
In a common gel electrophoresis setup, a nucleic acid such as DNA is loaded
into wells at one end of the gel and then migrates toward the positive electrode
at the opposite end. The rate of migration of fragments varies with size. The
steps of gel electrophoresis are shown below.
– The DNA samples are cut with a restriction enzyme into smaller
segments of various sizes. The DNA is then placed in wells made on a
thick gel.
– An electric current runs through the gel for a given period of time.
Negatively charged DNA fragments migrate toward the positively
charged end of the porous gel. Smaller DNA fragments migrate faster
and farther than longer fragments, and this separates the fragments by
size. The gel floats in a buffer solution within a chamber between two
electrodes.
– The DNA is transferred to a nylon membrane and radioactive probes
are added. The probes bind to complementary DNA.
– The X-ray film is exposed to the radiolabeled membrane. The resulting
pattern of bands is called a DNA fingerprint.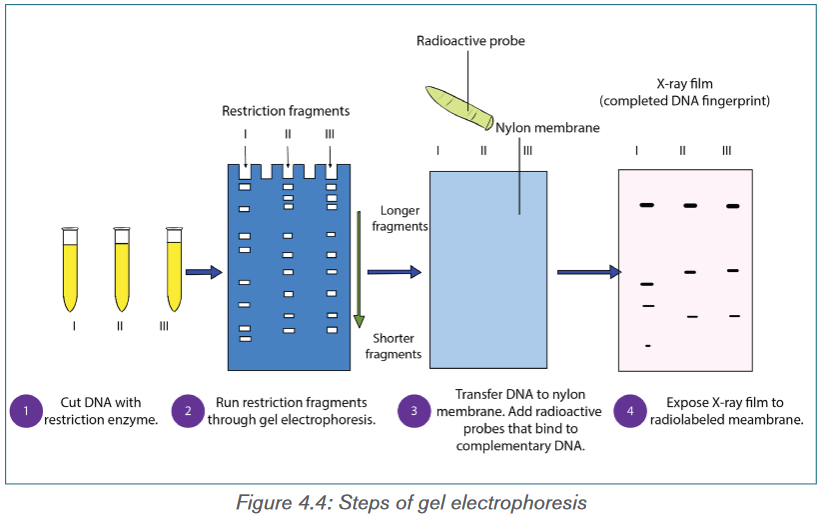
During electrophoresis, DNA fragments migrate through the gel at a rate that
is inversely proportional to the logarithm of their size. The shorter the fragment
is, the faster it will travel because of its ability to navigate through the pores in
the gel more easily than a large fragment can. Larger fragments are hampered
by their size. Hence, the longer a nucleotide chain, the longer it takes for the
migration.Gel electrophoresis takes advantage of DNA’s negative charge. A solution
containing different-size fragments to be separated is placed in a well. A
well is a depression at one end of the gel. The gel itself is usually a square or
rectangular slab and consists of a buffer containing electrolytes and agarose,
or possibly polyacrylamide. Agarose is a gel-forming polysaccharide found in
some types of seaweed that is used to form a gel meshwork for electrophoresis.
Polyacrylamide is an artificial polymer used to form a gel meshwork for
electrophoresis.The gel is loaded while it is submerged in a tray containing an electrolytic solution
called the buffer. Using direct current, a negative charge is placed at one end
of the gel where the wells are, and a positive charge is placed at the opposite
end of the gel. The electrolyte solution conveys the current through the gel. The
negatively charged DNA will migrate toward the positively charged electrode,
with the shorter fragments migrating faster than the longer fragments, achieving
separation. Small molecules found within the loading dye migrate ahead of all
the DNA fragments. Since the small molecules can be visualized, the electrical
current can be turned off before they reach the end of the gel.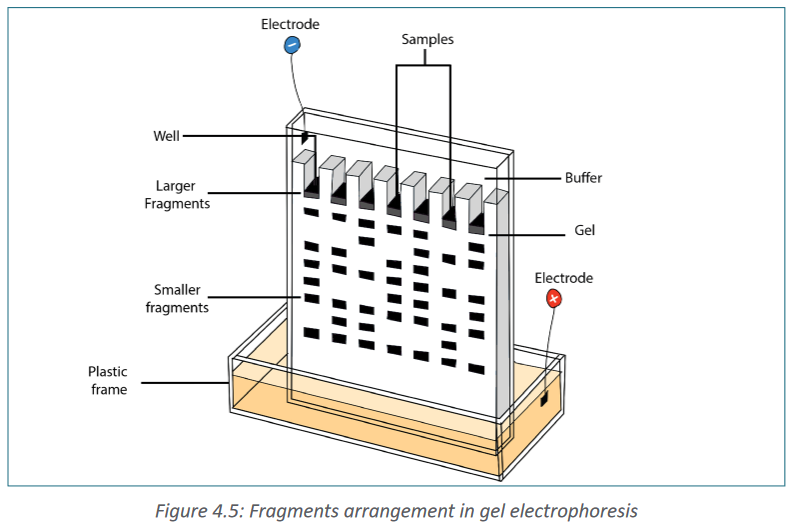
Once gel electrophoresis is complete, the DNA fragments are made visible by
staining the gel. The set of fragments generated with a particular restriction
enzyme produces a banding pattern characteristic for that DNA. The most
commonly used stain is ethidium bromide. Ethidium bromide is a flat molecule
that fluoresces under ultraviolet (UV) light and is able to insert itself among the
rungs of the ladder of DNA. When the gel is subjected to UV light, the bands
of DNA are visualized because the ethidium bromide is inserted among the
nucleotides. The size of the fragments is then determined using a molecular
marker as a standard. The molecular marker, which contains fragments of known
size, is run under the same conditions (in the same gel) as the digested DNA.Gel electrophoresis is not limited to the separation of nucleic acids but is also
commonly applied to proteins. Proteins are usually run on polyacrylamide
gels, which have smaller pores, because proteins are generally smaller in size
than nucleic acids. Proteins, however, are not negatively charged; thus, when
researchers want to separate proteins using gel electrophoresis, they must
first mix the proteins with a detergent called sodium dodecyl sulfate. This
treatment makes the proteins unfold into a linear shape and coats them with a
negative charge, which allows them to migrate toward the positive end of the gel
and be separated. Finally, after the DNA, RNA, or protein molecules have been
separated using gel electrophoresis, bands representing molecules of different
sizes can be detected. The gel electrophoresis is used for different purposes
such as DNA analysis, protein and antibody interactions, testing antibiotics and
testing vaccines.Application activity 4.4
The gel shown in the figure below was run after bacterial DNA was digested
using restriction enzymes where A, B, C and D are the comb lane of the gel.
In your notebook, indicate on the gel
a) Where the positive electrode was located;
b) Where the negative electrode was located;
c) The location of the largest band;
d) The location of the smallest band;
e) The number of cuts that were made on the linear fragment of DNA to
produce this number of bands.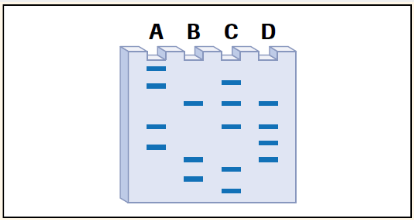
4.5 Production of human proteins by recombinant DNA
technologyActivity 4.4
The figure below shows the process by which bacteria can be bioengineered
to produce human insulin. Follow each of the steps used to produce GMO
bacteria. Use the figure to make a list of steps followed when producing
a genetically modified organism bacterium.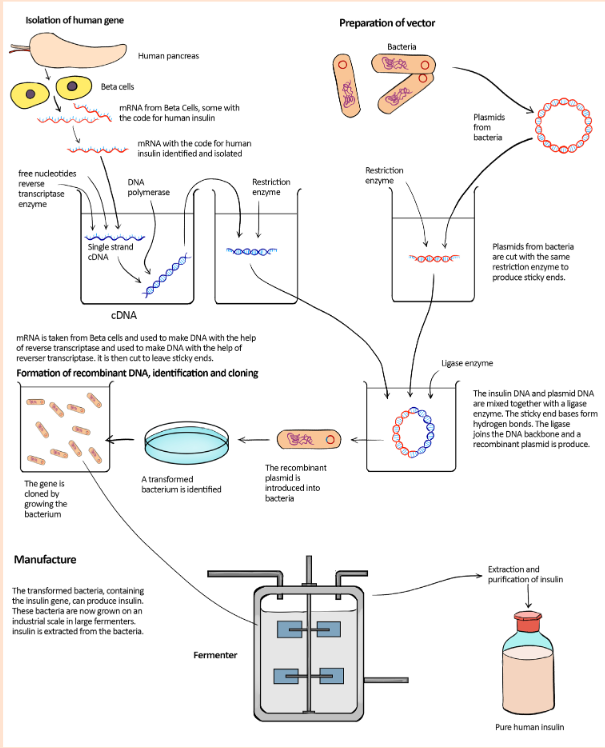
Production of insulin
One form of diabetes mellitus is caused by the inability of the pancreas to
produce insulin. Before insulin from GM bacteria became available, people with
this form of diabetes were treated with insulin extracted from the pancreases
of pigs or cattle. In the 1970s, biotechnology companies began to work on the
idea of inserting the gene for human insulin into a bacterium and then using
this bacterium to make insulin. They tried several different approaches, finally
succeeding in the early1980s. This form of human insulin became available
in1983.The procedure involved in the production of insulin is shown in the figure 4.6.
There were problems in locating and isolating the gene coding for human
insulin from all of the rest of the DNA in a human cell. Instead of cutting out
the gene from the DNA in the relevant chromosome, researchers extracted
mRNA for insulin from pancreatic β cells, which are the only cells to express
the insulin gene. These cells contain large quantities of mRNA for insulin as
they are its only source in the body. The mRNA was then incubated with the
enzyme reverse transcriptase which comes from the group of viruses called
retroviruses. As its name suggests, this enzyme reverses transcription, using
mRNA as a template to make single-stranded DNA. These single-stranded DNA
molecules were then converted to double-stranded DNA molecules using DNA
polymerase to assemble nucleotides to make the complementary strand. The
genetic engineers now had insulin genes that they could insert into plasmids to
transform the bacterium Escherichia coli.The main advantage of this form of insulin is that there is now a reliable supply
available to meet the increasing demand. Supplies are not dependent on factors
such as availability through the meat trade.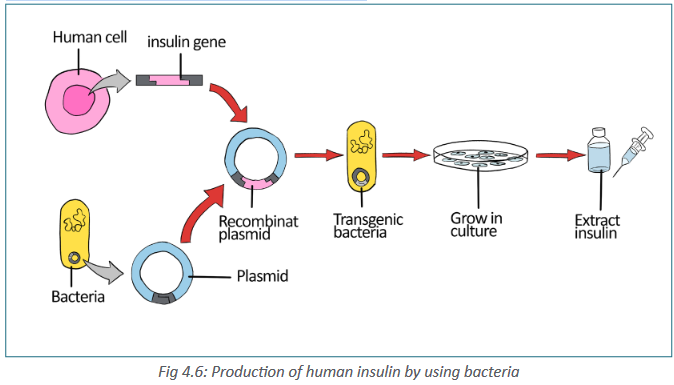
There were problems in locating and isolating the gene coding for human insulin
from all of the rest of the DNA in a human cell. Instead of cutting out the gene
from the DNA in the relevant chromosome, these are steps involved in human
insulin production:
– Researchers extracted mRNA for insulin from pancreatic β cells, which
are the only cells to express the insulin gene. These cells contain large
quantities of mRNA for insulin as they are its only source in the body.
– The mRNA was then incubated with the enzyme reverse transcriptase
which comes from the group of viruses called retroviruses. As its name
suggests, this enzyme reverses transcription, using mRNA as a template
to make single stranded DNA.
– These single-stranded DNA molecules were then converted to
double stranded DNA molecules using DNA polymerase to assemble
nucleotides to make the complementary strand.
– The genetic engineers now had insulin genes that they could insert into
plasmids to transform the bacterium Escherichia coli.
– When the bacterial cells copy their own DNA, they also copy the
plasmids and the donor genes that plasmids carry. After the cells have
grown into colonies, on an industrial scale in large fermenters insulin is
extracted from the bacteria.Production of bovine growth hormone
Recombinant (r) bovine growth hormone is a protein that has been made by
manipulating the DNA sequence (gene) that carries the instructions for, or
encodes, the growth hormone protein so it can be produced in the laboratory.
Hormones are substances secreted from specialized glands. Hormones travel
through the bloodstream to affect their target organs. Growth hormone acts on
many different organs to increase the overall size of the body. Before the advent
of genetic technologies, growth hormone was procured from the pituitary glands
of slaughtered cows and then injected into live cows.The same technique has been used to obtain human growth hormone from
the pituitary glands of human cadavers. When the human growth hormone is
injected into humans who have a condition called pituitary dwarfism, their size
increases. However, harvesting the growth hormone from the pituitary glands
of cows and humans is laborious, and many cadavers are necessary to obtain
small amounts of the protein.Producing rBGH
The first step in the production of the rBGH protein is to transfer the BGH gene
from the nucleus of a cow cell into a bacterial cell. Bacteria with the BGH gene
will then serve as factories to produce millions of copies of this gene and its
protein product; making many copies of a gene is called cloning the gene.Cloning a gene using bacterial cells
The following steps are involved in moving a BGH gene into a bacterial cell:
a) BGH gene is cut from the cow chromosome using restriction enzymes
that leave “sticky ends” with specific base sequences.
b) A plasmid from a bacterium is cut with the same restriction enzymes,
creating the same “sticky ends” as the cow gene.
c) The cleaved gene and plasmid are placed together in a test tube.
Complementary “sticky ends” fit together, resulting in a recombinant
plasmid.
d) The recombinant plasmid is reinserted into a bacterial cell.
e) The plasmids and the bacterial cells replicate, making millions of copies
of the rBGH gene.
f) The rBGH genes produce large quantities of rBGH proteins that are
harvested, purified, and injected into cows to increase milk production.Application activity 4.4
1) Rearrange the statements below to produce a flow diagram showing
the steps involved in producing bacteria capable of synthesizing a
human protein such as human growth hormone (hGH).
1. Insert the plasmid into a host bacterium.
2. Isolate mRNA for hGH.
3. Insert the DNA into a plasmid and use ligase to seal the ‘nicks’ in
the sugar–phosphate chains.
4. Use DNA polymerase to clone the DNA.
5. Clone the modified bacteria and harvest hGH.
6. Use reverse transcriptase to produce cDNA.
7. Use a restriction enzyme to cut a plasmid vector.4.6 Use of microarrays in the analysis of genomes and in
detecting mRNAActivity 4.6.
Indicate and explain the use and applications of the microarray DNA
technologyA DNA microarray consists of tiny amounts of a large number of single-stranded
DNA fragments representing different genes fixed to a glass slide in a tightlyspaced array, or grid. (The microarray is also called a DNA chip by analogy to a
computer chip.) Ideally, these fragments represent all the genes of an organism.The mRNA from the organism or the cell to be tested is labelled with a fluorescent
dye and added to the chip. When the mRNAs bind to the microarray, a fluorescent
pattern results that is recorded by a computer. Now the investigator knows what
DNA is active in that cell or organism. A researcher can use this method to
determine the difference in gene expression between two different cell types,
such as between liver cells and muscle cells.A mutation microarray, the most common type, can be used to generate a
person’s genetic profile. The microarray contains hundreds to thousands
of known disease-associated mutant gene alleles. Genomic DNA from the
individual to be tested is labelled with a fluorescent dye, and then added to
the microarray. The spots on the microarray fluoresce if the individual’s DNA
binds to the mutant genes on the chip, indicating that the individual may have
a particular disorder or is at risk for developing it later in life. This technique
can generate a genetic profile much more quickly and inexpensively than older
methods involving DNA sequencing.Microarrays have proved a valuable tool to identify the genes present in an
organism’s genome and to find out which genes are expressed within cells.
They have allowed researchers to study very large numbers of genes in a short
period of time, increasing the information available. A microarray is based on a
small piece of glass or plastic usually 2 cm2 (Figure 4.7). Short lengths of single-
stranded DNA are attached to this support in a regular two-dimensional pattern,
with 10 000 or more different positions per cm2. Each individual position has
multiple copies of the same DNA probe. It is possible to search databases to
find DNA probes for a huge range of genes. Having selected the gene probes
required, an automated process applies those probes to the positions on the
microarray.
When microarrays are used to analyze genomic DNA, the probes are from
known locations across the chromosomes of the organism involved and are
500 or more base pairs in length. A single microarray can even hold probes from
the entire human genome.Microarrays can be used to compare the genes present in two different species.
DNA is collected from each species and cut up into fragments and denatured
to give lengths of single-stranded DNA. The DNA is labelled with fluorescent
tags so that – for example – DNA from one species may be labelled with green
tags and DNA from the other species labelled with red tags. The labelled DNA
samples are mixed together and allowed to hybridize with the probes on the
microarray. Any DNA that does not bind to probes on the microarray is washed
off. The microarray is then inspected using ultraviolet light, which causes the
tags to fluoresce. Where this happens, we know that hybridization has taken
place because the DNA fragments are complementary to the probes. Green
and red fluorescent spots indicate where DNA from one species only has
hybridized with the probes. Where DNA from both species hybridize with a
probe, a yellow colour is seen. Yellow spots indicate that the two species have
DNA with exactly the same base sequence. This suggests that they have the
same genes (Figure 4.8). The microarray is then scanned so that the data can
be read by a computer. Data stored by the computer indicate which genes are
present in both species, which genes are only found in one of the species and
which genes are not present in either species.
Using microarray analysis, researchers can quickly compare gene expression in
different samples, such as those obtained from normal and cancerous tissues.
The knowledge gained from such gene expression studies is making a significant
contribution to the study of cancer and other diseases.Application activity 4.6.
Using your knowledge of the microarray DNA technology, explain three uses
of this technique.4.7 Gene therapy and genetic screening
Activity 4.7
Gene technology can be involved in the detection and treatment of genetic
disorders. Discuss on different cases of genetic disorders that are treated by
using gene therapy.4.7.1 Genetic screening
Genetic screening is the analysis of a person’s DNA to check for the presence
of a particular allele. This can be done in adults, in a foetus or embryo in the
uterus, or in a newly formed embryo produced by in vitro fertilisation. An adult
woman with a family history of breast cancer may choose to be screened for the
faulty alleles of the genes Brca-1 and Brca-2, which considerably increase an
individual’s chance of developing breast cancer. Should the results be positive,
the woman may elect to have her breasts removed (elective mastectomy) before
such cancer appears.In 1989, the first ‘designer baby’ was created. Officially known as pre-implantation
genetic diagnosis (PGD), the technique involved mixing the father’s sperm with
the mother’s eggs (oocytes) in a dish – that is, a ‘normal’ IVF procedure. It was
the next step that was new. At the eight-cell stage, one of the cells from the tiny
embryo was removed. The DNA in the cell was analysed and used to predict
whether or not the embryo would have a genetic disease for which both parents
were carriers. An embryo that was not carrying the allele that would cause the
disease was chosen for implantation, and embryos that did have this allele were
discarded.Since then, many babies have been born using this technique. It has been used
to avoid pregnancies in which the baby would have had Duchenne muscular
dystrophy, thalassaemia, haemophilia, Huntington’s disease and others. In
2004, it was first used in the UK to produce a baby that was a tissue match with
an elder sibling, with a view to using cells from the umbilical cord as a transplant
into the sick child.For some time, genetic testing of embryos has been leaving prospective parents
with very difficult choices to make if the embryo is found to have a genetic
condition such as Down’s syndrome or cystic fibrosis. The decision about
whether or not to have a termination is very difficult to make. Now, though,
advances in medical technology have provided us with even more ethical issues
to consider.4.7.2 Gene therapy
Gene therapy is the alteration of a genetic sequence in an organism to prevent
or treat a genetic disorder.Gene technology and our rapidly increasing knowledge of the positions of
particular genes on our chromosomes have given us the opportunity to identify
many genes that are responsible for genetic disorders such as sickle cell anaemia
and cystic fibrosis. When genetic engineering really began to get going in the
1990s, it was envisaged that it would not be long before gene technology could
cure these disorders by inserting ‘normal’ alleles of these genes into the cells.Gene therapy has proved to be far more difficult than was originally thought. The
problems lie in getting normal alleles of the genes into a person’s cells and then
making them work properly when they get there. In theory, a normal allele of the
defective gene could be inserted into the somatic cells of the tissue affected by
the disorder. For gene therapy of somatic cells to be permanent, the cells that
receive the normal allele must be ones that multiply throughout the patient’s life.
Bone marrow cells, which include the stem cells that give rise to all the cells
of the blood and immune system, are prime candidates. One type of severe
combined immunodeficiency (SCID) is caused by a single defective gene. If the
treatment is successful, the patient’s bone marrow cells will begin producing
the missing protein, and the patient will be cured.The most common vectors that are used to carry the normal alleles into host cells
are viruses (often retroviruses or lentiviruses) or small spheres of phospholipid
called liposomes. Occasionally ‘naked’ DNA is used. The first successful
gene therapy was performed in 1990 on a four-year-old girl from Cleveland,
Ohio. She suffered from the rare genetic disorder known as severe combined
immunodeficiency (SCID). In this disorder, the immune system is crippled and
sufferers die in infancy from common infections. Children showing the condition
are often isolated inside plastic ‘bubbles’ to protect them from infections.Application activity 4.7
DNA technology is increasingly being used in the diagnosis of genetic and
other diseases and offers potential for better treatment of genetic disorders
or even permanent cures. Suggest the advantages of genetic screening and
therapy over the normal methods of treating diseases.4.8 Genetically modified organisms in agriculture
Activity 4.8
Discuss on the different GMO used in agriculture and the possible advantages
of these plants over the natural plants.4.8.1 Gene technology and agriculture
Many new products have been developed using this technology. Crops have
been genetically engineered to increase yield, hardiness, uniformity, insect and
virus resistance, and herbicide tolerance. The vast bulk of genetically modified
plants grown around the world are crop plants modified to be resistant to
herbicides or crops that are resistant to insect pests. These modifications
increase crop yield. A few crops, such as vitamin A, enhanced rice, provide
improved nutrition.4.8.2 Use of Agrobacterium tumefaciens to transfer genes
in plantsAgrobacterium is a bacterium that uses a horizontal gene transfer (HGT).
HGT is the transfer of DNA between different genomes. HGT can occur in
bacteria through transformation, conjugation and transduction. However, it is
also possible for HGT to occur between eukaryotes and bacteria. Bacteria have
three ways of transferring bacteria DNA between cells:1) Transformation: The uptake and incorporation of external DNA into the
cell thereby resulting in the alteration of the genome.2) Conjugation: The exchange of genetic material through cell-to-cell
contact of two bacterial cells. A strand of plasmid DNA is transferred to
the recipient cell and the donor cell then synthesis DNA to replace the
strand that was transferred to the recipient cell.3) Transduction: A segment of bacterial DNA is carried from one bacterial
cell to another by a bacteriophage. The bacteriophage infects a bacterial
cell and takes up bacterial DNA. When this phage infects another cell,
it transfers the bacterial DNA to the new cell. The bacteria can then
become a part of the new host cell.Agrobacterium has the ability to transfer DNA between itself and plants
and is therefore commonly used in genetic engineering. The process of using
Agrobacterium for genetic engineering is illustrated in the diagram below.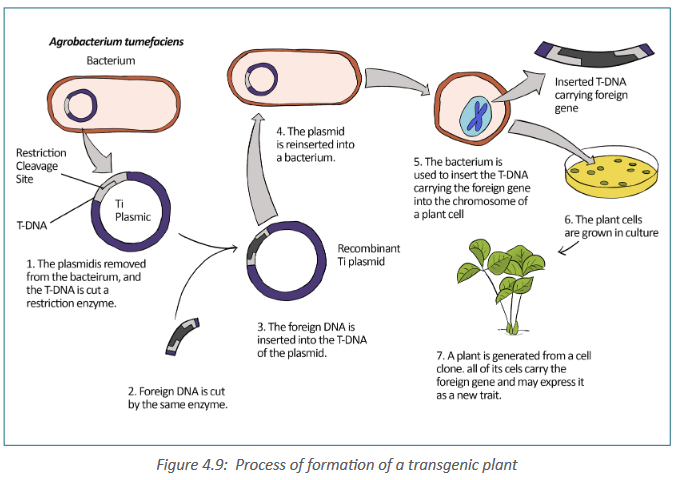
Summary of formation of a transgenic plant:
– The Agrobacterium cell contains a bacterial chromosome and a Tumor
inducing plasmid (Ti Plasmid).
– The Ti plasmid is removed from the agrobacterium cell and a restriction
enzyme cleaves the T-DNA restriction site.
– The foreign gene of interest is inserted into the middle of the TDNA.
– Recombinant plasmids can be introduced into cultured plant cells by
electroporation. Or plasmids can be returned to Agrobacterium, which
is then applied as a liquid suspension to the leaves of susceptible
plants, infecting them. Once a plasmid is taken into a plant cell, its
TDNA integrates into the cell’s chromosomal DNA.a. Golden rice
Golden rice is a staple food in many parts of the world, where people are
poor and rice forms the major part of their diet. Deficiency of vitamin A is a
common and serious problem; its deficiency can cause blindness. In the 1990s,
a project was undertaken to produce a variety of rice that contained carotene in
its endosperm. Genes for the production of carotene were extracted from maize
and the bacterium Pantonoea ananatis. These genes, together with promoters,
were inserted into plasmids. The plasmids were inserted into bacteria called
Agrobacterium tumefaciens. These bacteria naturally infect plants and so could
introduce the genetically modified plasmid into rice cells. The rice embryos, now
containing the carotene genes, were grown into adult plants.This genetically modified rice is called golden rice, because it contains a lot of
yellow pigment carotene. The genetically modified rice is being bred into other
varieties of rice to produce varieties that grow well in the conditions in different
parts of the world, with the same yield, pest resistance and eating qualities as
the original varieties.
b. Herbicide-resistant crops
Herbicide-resistant crops called oil seed rape or Brassica napus, is grown in
many parts of the world as a source of vegetable oil which is used as biodiesel
fuel, as a lubricant and in human and animal foods. Natural rape seed oil contains
substances that are undesirable in oil that is to be used in human or animal
food. A hybrid, was made to produce low concentrations of these undesirable
substances, called canola (Canadian oilseed low acid), and this name is
now often used to mean any variety of oil seed rape. Gene technology has been
used to produce herbicide-resistant strains. Growing an herbicide-resistant
crop allows fields to be sprayed with herbicide after the crop has germinated,
killing any weeds that would otherwise compete with the crop for space, light,
water or ions. This increases the yield of the crop.c. Insect pests-resistant plants
Another important agricultural development is that of genetically modified plants
protected against attack by insect pests. Bt maize is genetically engineered
(GE) plant that produces crystal (Cry) proteins or toxins derived from the soil
bacterium, Bacillus thuringiensis (Bt), hence the common name “Bt maize”. Bt
maize plant has revolutionized pest control in a number of countries, but there
still are questions about its use and impact.Application activity 4.8
Explain why are Ti plasmids are used to insert genes into plant cells?
4.9 Significance of genetic engineering in improving the
quality and yield of crop plants and livestockActivity 4.9
The figure below shows an Atlantic salmon and a GMO salmon. A GM salmon
and non-GM salmon are of the same age.
Suggest any advantage of growing GM salmon over non-GM salmon and
discuss how the GM salmons are produced.4.9.1 Why are animals genetically modified?
Genetically modified animals are animals that have been genetically
modified for a variety of purposes including producing drugs, enhancing
yields, increase resistance to disease, etc. The vast majority of genetically
modified animals are at the research stage with the number close to entering
the market remains small. The process of genetically engineering mammals is a
slow, tedious, and expensive process. Researchers have genetically engineered
a number of mammals, from laboratory animals to farm animals, as well as birds,
fish and insects.The most widely used genetically modified animals are laboratory animals, such
as the fruitfly (Drosophila) and mice. Genetically engineered animals enable
scientists to gain an insight into basic biological processes and the relationships
between mutations and disease. However, farm animals, such as sheep, goats
and cows, can also be genetically modified to enhance specific characteristics.
These can include milk production and disease resistance, as well as improving
the nutritional value of the products they are farmed for. For example, cows,
goats and sheep have been genetically engineered to express specific proteins
in their milk.The majority of work on genetically modified farm animals is still in the research
phase and is yet to be used commercially. The advantages and disadvantages
associated with genetically modifying animals for agriculture, divided up into
four key areas: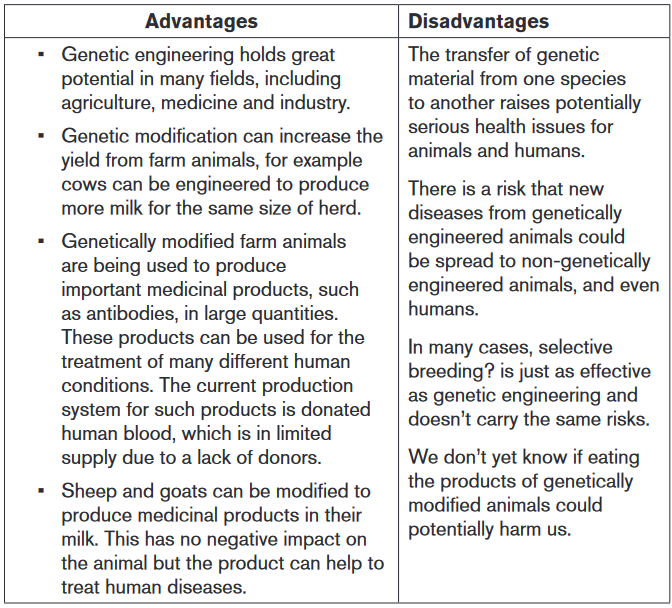
4.9.2 Why are crop plants genetically modified?
Crop plants are genetically modified to increase their shelf life, yield and nutritive
value.• To increase the shelf life: to increase the time of ripening and the time of
storage.
• Improving the yield of crop plants has been the driving force behind the
vast majority of genetic engineering. Yield can be increased when plants
are engineered to be resistant to pesticides and herbicides, drought, and
freezing. For example, a gene from an Arctic fish has been transferred into
a strawberry to help prevent frost damage.Many people believe that improving farmers’ yields may help decrease world
hunger problems. Others argue that, since there is already enough food being
produced to feed the entire population, it might make more sense to use less
technological approaches to feeding the hungry. Significant numbers of people
around the world are malnourished, hungry, or starving, not due to a shortage of
food but because access to food is tied to access to money or land.• Genetic engineers may also be able to increase the nutritive value of crops.
Some genetic engineers have increased the amount of β -carotene in
rice, a staple food for many of the world’s people. Scientists hope the
engineered rice will help decrease the number of people who become
blind in underdeveloped nations because cells require β-carotene in order
to synthesize vitamin A, a vitamin required for vision. Therefore, eating this
genetically modified rice, called Golden Rice, increases a person’s ability
to synthesize vitamin A.Application activity 4.9
a) What is the importance of using golden rice in developing countries?
b) Suggest any three importance of using GM organism?4.10 Ethical and social implications of using genetically
modified organisms (GMOs).Activity 4.10
From your daily life experience, discuss the ethical and social implications of
using genetically modified crops in food production.Ethics includes moral principles that control or influence a person’s behaviour.
It includes a set of standards by which a community regulates its behaviour
and decides as to which activity is legitimate and which is not. Bioethics maybe viewed as a set of standards that may be used to regulate our activities in
relation to the biological world. Biotechnology, particularly recombinant DNA
technology, is used for exploitation of the biological world by various ways.Some genetically modified plants are grown in strict containment of glasshouses,
but a totally different set of problems emerges when genetically engineered
organisms such as crop plants and organisms for the biological control of pests
are intended for use in the general environment. Few countries would object
to the growth of genetically modified crops that produce vaccines for human
or animal use, yet there are people who object to the growth of pro-vitamin A
enhanced rice. The major bioethical concerns pertaining to biotechnology are
summarized below:
– When animals are used for production of certain pharmaceutical
proteins, they are treated as factory machines.
– Introduction of a transgene from one species into another species
violates the integrity of species.
– The transfer of human genes into animals or vice-versa is great ethic
threat to humanity.
– Biotechnology is disrespectful to living beings, and only exploits them
for the benefit of humans.
– Genetic modification of organism can have unpredictable/ undesirable
effects when such organisms are introduced into the ecosystem.Moreover, most objections are raised against the growth of herbicide-resistant
or insect-resistant crops as follow:
– The modified crop plants may become agricultural weeds or invade
natural habitats.
– The introduced gene may be transferred by pollen to wild relatives
whose hybrid offspring may become more invasive.
– The introduced gene may be transferred by pollen to unmodified plants
growing on a farm with organic certification.
– The modified plants may be a direct hazard to humans, domestic animals
or other beneficial animals, by being toxic or producing allergies.
– The herbicide that can now be used on the crop will leave toxic residues
in the crop.
– Genetically modified seeds are expensive, as is herbicide, and their
cost may remove any advantage of growing a resistant crop.
– Growers mostly need to buy seed each season, keeping costs high,
unlike for traditional varieties, where the grower kept seed from one
crop to sow for the next– In parts of the world where a lot of genetically modified crops are grown,
there is a danger of losing traditional varieties with their desirable
background genes for particular localities This requires a program of
growing and harvesting traditional varieties and setting up a seed bank
to preserve them.
Application activity 4.10
Discuss ethical and social implications raised against insect-resistant crops.
4.11 Bioinformatics
Activity 4.11
Dicuss on the importance of Bioinformatics and its importance. Thereafter;
Explain how the bioinformatics has contributed to the progress in DNA
sequence analysis.Bioinformatics is the collection, processing and analysis of biological
information and data using computer software. In other words, it is the branch
of biology that is concerned with the acquisition, storage, and analysis of the
information found in nucleic acid and protein sequence data. Bioinformatics
combines biological data with computer technology and statistics. It builds up
databases and allows links to be made between them. The databases hold
gene sequences of complete genomes, amino acid sequences of proteins and
protein structures.4.11.1 Scientists use bioinformatics to analyze genomes
and their functions
Different government agencies carried out their mandate to establish databases
and provide software with which scientists could analyse the sequence data. For
example, in the United States, a joint endeavour between the National Library of
Medicine and the National Institutes of Health (NIH) created the National
Center for Biotechnology Information (NCBI), which maintains a website
(www.ncbi.nlm.nih.gov) with extensive bioinformatics resources. On this site are
links to databases, software, and a wealth of information about genomics and
related topics. Similar websites have also been established by the European
Molecular Biology Laboratory (EMBL) and the DNA Data Bank of Japan,
two genome centers with which the NCBI collaborates.These large, comprehensive websites are complemented by others maintained
by individual or small groups of laboratories. Smaller websites often provide
databases and software designed for a narrower purpose, such as studying
genetic and genomic changes in one particular type of cancer.The NCBI database of sequences is called Genbank. As of August 2007, it
included the sequences of 76 million fragments of genomic DNA, totaling 80
billion base pairs! Genbank is constantly updated, and the amount of data it
contains is estimated to double approximately every 18 months. Any sequence
in the database can be retrieved and analyzed using software from the NCBI
website or elsewhere.UniProt (universal protein resource) holds information on the primary sequences
of proteins and the functions of many proteins, such as enzymes. The search tool
BLAST (basic local alignment search tool) is an algorithm for comparing primary
biological sequence information, such as the primary sequences of different
proteins or the nucleotide sequences of genes. Researchers use BLAST to find
similarities between sequences that they are studying and those already saved
in databases. When a genome has been sequenced, comparisons can be made
with other known genomes. For example, the human genome can be compared
to the genomes of the fruit fly, Drosophila, the nematode worm, or the malarial
parasite, Plasmodium. All the information about the genome of Plasmodium is
now available in databases. This information is being used to find new methods
to control the parasite. For example, being able to read gene sequences is
providing valuable information in the development of vaccines for malaria.4.11.2 Applications of bioinformatics
Bioinformatics has various applications in human genetics. For example,
researchers found the function of the protein that causes cystic fibrosis by
using the computer to search for genes in model organisms that have thesame sequence. Because they knew the function of this same gene in model
organisms, they could deduce the function in humans. This was a necessary
step toward possibly developing specific treatments for cystic fibrosis. The
human genome has 3 billion known base pairs, and without the computer it
would be almost impossible to make sense of these data. For example, it is now
known that an individual’s genome often contains multiple copies of a gene. But
individuals may differ as to the number of copies called copy number variations.
Now it seems that the number of copies in a genome can be associated with
specific diseases. The computer can help make correlations between genomic
differences among large numbers of people and disease. It is safe to say
that without bioinformatics, our progress in determining the function of DNA
sequences; in comparing our genome to model organisms; in knowing how
genes and proteins interact in cells; and so forth, would be extremely slow.
Instead, with the help of bioinformatics, progress should proceed rapidly in
these and other areas.Application activity 4.11
a) Describe 2 applications of bioinformatics
b) Explain the role of bioinformatics following the sequencing of genome of
Plasmodium in the control and prevention of malaria.Skills lab 4
Sensitize people about the use of DNA in crime investigation
In violent crimes, body fluids or small pieces of tissue may be left at the scene
or on the clothes or other possessions of the victim or assailant. If enough
blood, semen, or tissue is available, forensic laboratories can determine the
blood type or tissue type by using antibodies to detect specific cell-surface
proteins. However, such tests require fairly fresh samples in relatively large
amounts. Also, because many people have the same blood or tissue type,
this approach can only exclude a suspect; it cannot provide strong evidence
of guilt.DNA testing, on the other hand, can identify the guilty individual with a
high degree of certainty, because the DNA sequence of every person is
unique (except for identical twins).Genetic markers that vary in the population can be analyzed for a given person
to determine that individual’s unique set of genetic markers, or genetic profile.(This term is preferred over “DNA fingerprint” by forensic scientists, who want
to emphasize the heritable aspect of these markers rather than simply the
fact that they produce a pattern on a gel that, like a fingerprint, is visually
recognizable). The Rwanda Forensic Laboratory can now use DNA test to
convict criminals and to help to solve different problems such as paternity
testing.Student-teachers will have to sensitize people about the behavior that they
need to take for example if there is someone who has been murdered. They
will have to avoid to touching him because they can be taken as guilty or
they can make the police unable to find the murderer due to the fact that the
murdered person has been touched by a lot number of people.End unit assessment 4
I. Choose the letter corresponding to the best answer.
1) Different enzymes are used in the various steps involved in the
production of bacteria capable of synthesizing a human protein. Which
step is catalyzed by a restriction enzyme?
a) Cloning DNA
b) Cutting open a plasmid vector
c) Producing cDNA from mRNA
d) Reforming the DNA double helix2) What describes a promoter?
a) A length of DNA that controls the expression of a gene.
b) A piece of RNA that binds to DNA to switch off a gene.
c) A polypeptide that binds to DNA to switch on a gene
d) A triplet code of three DNA nucleotides that codes for ‘stop’3) Which statement correctly describes the electrophoresis of DNA
fragments?
a) Larger fragments of DNA move more rapidly to the anode than
smaller fragments.
b) Positively charged fragments of DNA move to the anode.
c) Small negatively charged fragments of DNA move rapidly to the
cathode.d) Smaller fragments of DNA move more rapidly than larger fragments.
II. OPEN ENDED QUESTIONS
1) The table shows enzymes that are used in gene technology. Copy and
complete the table to show the role of each enzyme.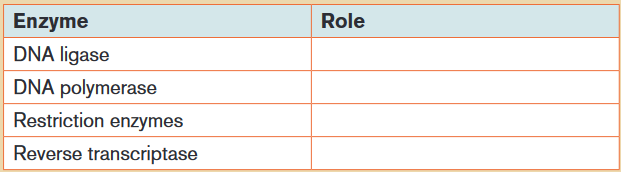
a) Explain what is meant by:
i) Gene therapy
ii) Genetic screening.
b) Explain why it is easier to devise a gene therapy for condition caused by
a recessive allele than for one caused by a dominant allele.
2) Refer to what you have studied on DNA and PCR,
a) How many molecules of DNA are produced from one double-stranded
starting molecule, after eight cycles of PCR?
b) Explain why it is not possible to use PCR to increase the number of
RNA molecules in the same way as it is used to increase the number of
DNA molecules.
3) The latest estimate of the number of genes in the human genome is 21
000. Before the invention of microarrays, it was very time consuming to
find out which genes were expressed in any particular cell.
a) Explain how it is possible to find out which genes are active in a cell at
a particular time in its development.
b) Why is it not possible to use the same technique to find out which
genes are active in red blood cells?III. Long Answer Type Questions
1) Bacteria are used in genetic engineering. The diagram outlines the
process of inserting human insulin genes into bacteria using genetic
engineering.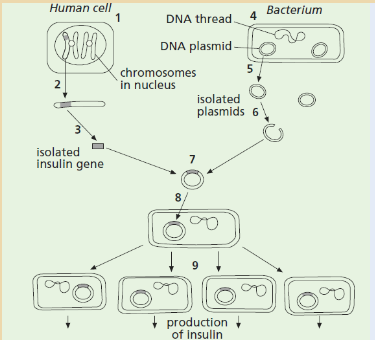
Complete the table below by identifying one of the stages shown in the
diagram that matches each description.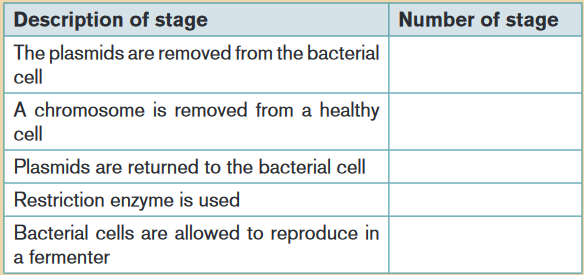
The diagram below shows a map of pBr322, a small piece of double-stranded,
circular DNA found in a bacterium in addition to the bacterial chromosome.
The genes for ampicillin resistance (Ampres) and tetracycline resistance (Tetres)
are indicated.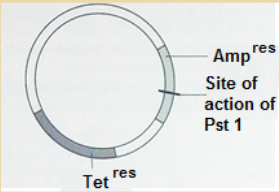
Pst 1 is a restriction endonuclease (enzyme) that has its effect at the site
shown. Pst 1 recognizes the base sequence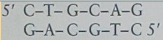 and acts on
and acts onthe DNA between guanine and adenine bases.
a) State the name given to such a piece of circular DNA.
b) Explain the use of such DNA in genetic engineering
c) Using the information given:
i) Explain what is meant by the term restriction endonuclease.
ii) Explain what is meant by the term sticky ends.