Unit 6 Protein Synthesis
Key Unit Competence
To be able to explain the relationship between a gene and the sequence of nucleotides in
DNA and to describe the process of protein synthesis in eukaryotes.
LEARNING OBJECTIVES
At the end of this unit, the learner will be able to:
• State the features of a genetic code.
• State that a gene is a sequence of nucleotides that form part of a DNA molecule that codes
for a specific polypeptide.
• Appreciate the importance of the genetic code in determining the structure of a protein.
• Describe how the information in DNA is used during transcription and translation to
construct polypeptides.
• Agree that the way DNA code for polypeptides is central to our understanding of how cells
and organisms function.
• Be aware that DNA is an extremely stable molecule that cells replicate with extreme accuracy
to minimise possibilities of DNA mutations.
• State the roles played by mRNA, tRNA and the ribosomes in the formation of the polypeptide.
• Appreciate the role of the genetic code in determining the characteristics of an individual.
• State that ribosomes provide surface area for the attachment of mRNA during polypeptide
synthesis.
• State that polysomes consists of up to 50 ribosomes on the same mRNA strand and that they
speed up polypeptide synthesis.
• Describe the way in which the nucleotide sequence codes for the amino acid sequence with
specific reference to HbA (normal) and HbS( sickle cell) alleles for b-globin poly peptides.
• State that gene mutation is a change in the sequence of nucleotides that may result in an
altered polypeptide.
• Construct a flow chart, in proper sequence, for the stages of transcription and translation.
• Using the evidence, predict the effect of change in genetic code on the structure of the protein
manufactured during protein synthesis.
• Carry out research to find and understand better about protein synthesis and on genetic diseases.
INTRODUCTORY ACTIVITY
You can refer to your notes of Bio S4 to answer the following questions:
1) Assort the list below into proteins and non- proteins:
Glucose – Enzymes – Cholesterol – Amylose – Keratin – Haemoglobin – Ascorbic
acid – Melanin – starch – Myosin
2) Why two ladies having the same diet can be one with long hairs and another with
short hairs?
6.1 GENETIC CODE
ACTIVITY 6.1
You have studied that codon is made up of three bases and DNAs in human body intermittently
open and close up during DNA replication and transcription, but how is it that genetic
information is passed on from generation to generation with minimal mistake? Research and
discuss your findings, and then list out the best answers. You may look into textbooks, videoclips, computer animations, Internet, etc for finding answers.
A gene is a sequence of nucleotides that forms part of a DNA molecule that codes for a specific
polypeptide.
The genetic code is the set of rules by which information encoded in genetic material (DNA
or RNA sequences) is translated into proteins (amino acid sequences) by living cells using
ribosome machinery. In other words, the genetic code is a set of rules that specify how the
nucleotides sequence (AUGC) of an m-RNA is translated into the amino acid sequence of a
polypeptide chain.
During translation, the process of making proteins, ribosome reads the sequence of an m-RNA
(nucleotide sequences) from 5’ end to 3’ end. Then it makes appropriate amino acids according
to the genetic information on the m-RNA. By nature in both eukaryotes and prokaryotes, the
5’ to 3’ nucleotide sequence of the coding DNA strand exactly corresponds or specifies thesame N-terminal to C-terminal amino acid sequence of the encoded polypeptide (Figure 6.1).
As studied in Unit 3, with four different nucleotides (A, C, G, U), a three-letter code (codon)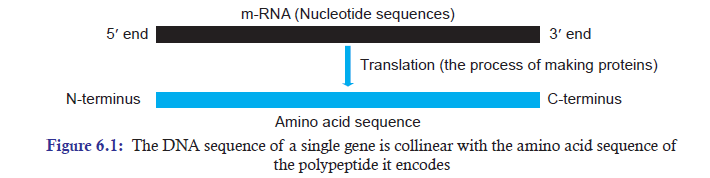
can give 64 different possible codons (i.e., 43 = 64) or (4 × 4 × 4 = 64). These 64 possible codons
are more than enough to code for the 20 amino acids found in living cells. The genetic code
allows an organism to translate the genetic information found in its chromosomes (m-RNA)into mature functional proteins.
6.1.1 The Characteristics of Genetic Code
The following are some characteristics of genetic code:
1. The Genetic Code is a Triplet Codon: A codon consists of a group of three nucleotides.
And each codon codes for a specific amino acid in a polypeptide chain with some exceptions.
2. The Genetic Code is Used without Comma: The three nucleotides in a codon are read
in a continuous fashion without any comma. Examples: AUG, UAG, UGA and UAA.
3. The Genetic Code is Non-overlapping: The codons in the m-RNA sequence are read
successively without overlapping.
4. The Genetic Code is Almost Universal: For many long years, it was thought that the
genetic code is universal, which led us into believing that all living organisms have the same
genetic code. However, recent studies have revealed that there are some organisms where
there is difference in genetic code (Table 6.1). That is the reason why it is appropriate
to use the phrase “almost universal” rather than the word “universal.” The examples of
organisms or organelles where genetic codes have different meanings:Table 6.1: Genetic Code
5. The Genetic Code is “Degenerate”: A codon is thought to code for a particular amino
acid. That is one codon for one amino acid. But more than one codon can code for a
particular amino acid, with two exceptions of AUG and UGG. This multiple coding by
a single codon is called the degeneracy or redundancy of the code. Example: UUU and
UUC codons code for the same specific phenylalanine amino acid. In the same way, CAUand CAC codons code for the same specific histidine amino acid (Figure 6.2).
Figure 6.2: The Genetic Code: Out of the total 64 codons, 61 sense codons specify one of the 20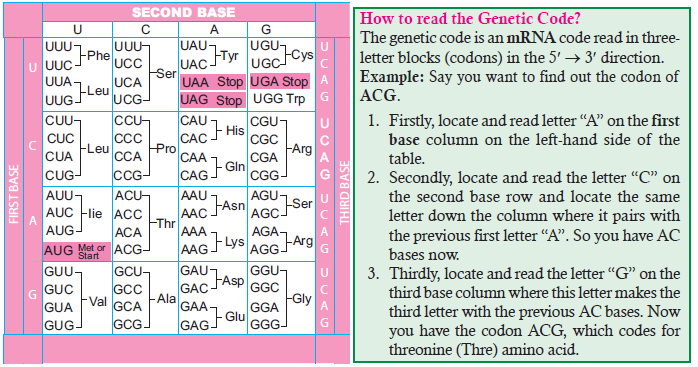
amino acids. The other three nonsense codons are Stop Codons and, therefore, do not specify anyacid. The sense codon AUG, which specifies Methionine, is a Start Codon
6. The Genetic Code has Start and Stop Codons: Out of 64 codons, only 61 codons are
called sense codons (Figure 6.2). The other three codons are called nonsense codons
or stop codons or chain-terminating codons. These three codons are UAG, UAA,
and UGA; they do not specify any amino acid, and there are no t-RNAs to carry the
appropriate anticodons. The AUG codon, which code for methionine, is most of the
time the start codon or initiation codon for protein synthesis in both eukaryotes and
prokaryotes.
7. Wobble Hypothesis: Francis Crick has pointed out that the complete set of 61 sense
codons can be read by fewer number than 61 t-RNAs. The simple reason being, the pairing
properties in the bases in the anticodons are wobble in nature. Here, the word “wobble”
simply means “fluctuating” or “unsteady.”
For example: The two different leucine codons (CUC, CUU) can be read by the sameleucine t-RNA molecule, contrary to regular base-pairing rules (Figure 6.3).
Figure 6.3: Example of base-pairing wobble. The same leucine t-RNA molecule (anticodon GAG)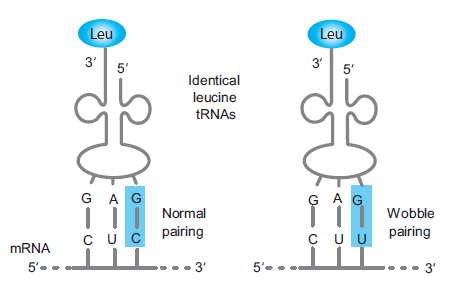
can read two different leucine codons (CUC, CUU)
6.1.2 Importance of the Genetic Code in Determining the Structure of a Protein
DNA is Extremely Stable and Replicates Accurately
According to central dogma concept, m-RNA is copied from DNA and m-RNA is then translated
to form proteins. Therefore, it is critical to maintain the integrity of DNA to accurately produce
the desired and correct amino acids (proteins).
DNA is the repository of genetic information gathered over millions of years and it is stored
in a stable form inside the cell. The stability of DNA is a property critical to the maintenance
of the integrity of the gene.
The stability of DNA can be explained and evidently supported by the fact that DNA has been
extracted from Egyptian mummies and extinct animals such as the woolly mammoth and it
can also be extracted from dried blood sample or from a single hair at a crime scene which is
old enough. DNA molecule is a stable structure and replicates accurately in order to avoid any
mutation or change in nucleotides sequences in DNA. The stability of DNA can be attributedto important factors — Hydrogen Bonds and Base Stacking.
Hydrogen Bonds
Hydrogen bond is the attractive force between the hydrogen attached to an electronegative
atom (O) of one molecule and an electronegative atom (N) of a different molecule
(Figure 6.4). In the structure of DNA, the strong electronegative atom is the oxygen (O) andNitrogen (N), while H atom has positive charge. In the structure of DNA (Figure 6.4), thymine
and adenine have two hydrogen bonds; while guanine and cytosine have three hydrogen bonds.
Hydrogen bonds play very important role in binding the bases of the opposite strands in the
DNA. Hydrogen bonds are very weak by themselves. But in a DNA sequence, there will bethousands of these H-bonds which make DNA very stable.
Figure 6.4: Hydrogen bonding and Base stacking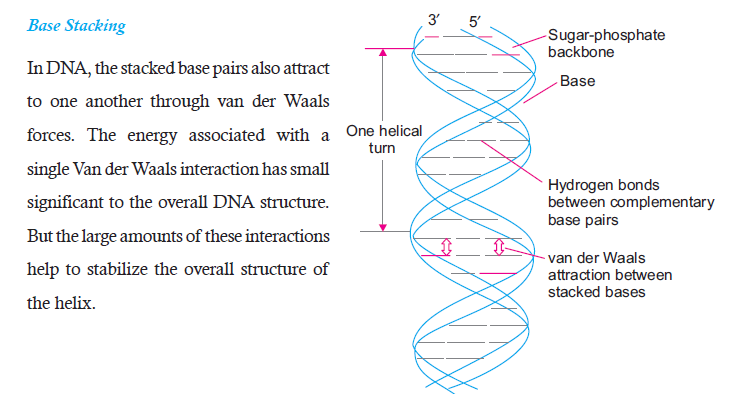
enabling stability of DNA
APPLICATION 6.1
1. Complete the sentence with correct word:
(a) A .............. is a sequence of nucleotide which codes for specific polypeptide.
(b) .............. allows an organism to translate genetic information into proteins.
(c) .............. is a start codon.
(d) .............. and .............. contributes to stability of DNA.
2. Describe briefly what is meant by Wobble Hypothesis3. Draw and label the structure of a t – RNA
6.2 TRANSCRIPTION
Transcription is the process of copying information from one strand of DNA into a singlestrandedRNA.
ACTIVITY 6.2
Discuss how DNA replication is different from the process of transcription. Make flow chart,
diagrams of bacterial and eukaryotic transcriptions. You can use for reference textbooks, videoclips, animation and Internet.
6.2.1 Transcription Unit in DNA
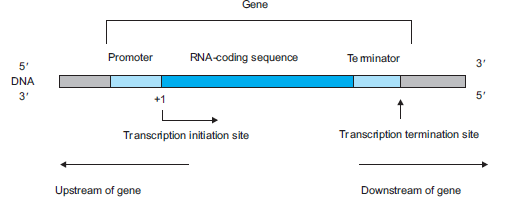
Figure 6.5: A transcription unit of DNA
Note:
- The nucleotide in the template strand at which transcription begins is designated with the
number +1.
- Downstream sequences are drawn, by convention, to the right of the transcription start site.
- Nucleotides that lie to the left of the transcription start site, are called the upstream sequences
and are identified by negative numbers.Note:
- The nucleotide in the template strand at which transcription begins is designated with the
number +1.
- Downstream sequences are drawn, by convention, to the right of the transcription start site.
- Nucleotides that lie to the left of the transcription start site, are called the upstream sequencesand are identified by negative numbers.
A transcription unit in DNA consists of three main regions (Figure 6.5):
(a) A promoter: A promoter is a region of DNA that initiates transcription of a particular
gene.
(b) RNA coding sequence: It is a DNA sequence that is transcribed by RNA polymerase
into RNA transcript (m-RNA).(c) A terminator: It is a DNA sequence which specifies termination of transcription.
6.2.2 RNA Polymerase
In bacteria, RNA polymerase is the only enzyme that is responsible for catalysing the process
of transcription. It is a DNA-dependent RNA polymerase, as it uses a DNA template strand
to synthesize a new RNA chain. During transcription, it synthesizes RNA in 5’ to 3’ direction
by using 3’ to 5’ strand of DNA as a template strand. The opposite 5’ to 3’ strand of DNA is
not used during transcription and it is called nontemplate strand.
RNA polymerase uses RNA precursors for synthesizing RNA chain. The RNA precursors are
ribonucleoside triphosphates ATP, GTP, CTP, and UTP. They are collectively known as NTPs
or Nucleoside triphosphate. The synthesis of RNA chain follows complementary base pairingrule i.e., A will pair with U; G will pair with C.
6.2.3 The Process of Transcription in Bacteria
The process of transcription is basically divided into three stages: (a) Initiation (b) Elongation
(c) Termination (Figure 6.6).
(a) Initiation: RNA polymerase accompanied by sigma (s) factor binds at the promoter.
Sigma factor ensures that RNA polymerase binds accurately and stably on the promoter.
Then RNA polymerase unwinds DNA in the promoter region to form open promoter
complex.
(b) Elongation: Once the initiation has commenced, RNA polymerase starts elongating or
adding NTPs one after the other using one of the strands of DNA as a template strand.
The nontemplate strand is not used for elongation of RNA. Elongation of the new RNA
takes place in 5’ to 3’ direction and follows complementary base pairing rule. For example:
If the DNA sequence in the DNA template is 3’-ATACTTGAACTAACTC-5’, then thesequence of newly synthesized RNA will be 5’-UAUGAACUUGAUUGAG-3’.
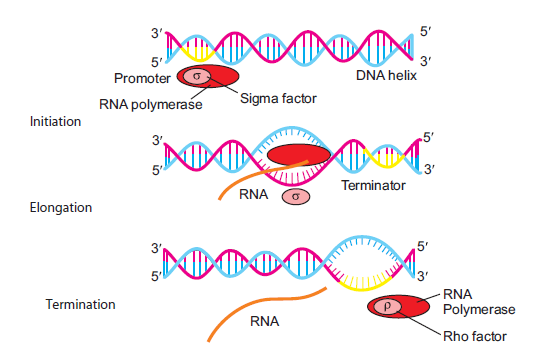
Figure 6.6: The process of transcription in bacteria
(c) Termination: Termination of transcription is signalled by terminator sequence located
downstream from the promoter. It can take place in two ways:
6.2.4 Transcription in Eukaryotes
Unlike the situation in prokaryotes, transcription in eukaryotes occurs within the nucleus and
mRNA moves out of the nucleus into the cytoplasm for translation. In eukaryotes, there are
two additional complexities:
1. There are at least three RNA polymerases in the nucleus (in addition to the RNA
polymerase found in the organelles). There are RNA polymerase I, II and III. The RNA
polymerase I transcribes rRNAs (285, 185 and 5.8S), whereas RNA polymerase III is
responsible for transcription of tRNA, RNA, 5s rRNA and sn RNAs (small nuclear
RNAs). The RNA polymerase II transcribes precursor of mRNA (pre-mRNA) or hnRNA
(heterogenous nuclear RNA). Thus, there is a division of labour in the functioning ofthe three types of RNA polymerase.
2. The second complexity is that the primary transcript contains two types of segments,
the non-coding introns or intervening sequences and the coding exons. The primary
eukaryotic mRNA transcript is much longer and is non-functional. Hence, it is subjected
to a process called ‘splicing’, where the introns are removed and exons are joined in a
definite order. Hn RNA (primary of RNA transcript) undergo two additional processing
called ‘capping’ and ‘tailing’. In capping an unusual nucleotide, methyl guanosine
triphosphate (mGppp) is added to the 5′ end of hn RNA. In ‘tailing’ adenylate residues
(200-300) are added (polyadenylation at 3′-end to hn RNA in a template independent
manner (i.e., without a template). The fully processed hnRNA is now called mRNA,that is transported out of the nucleus for translation (Figure 6.7).
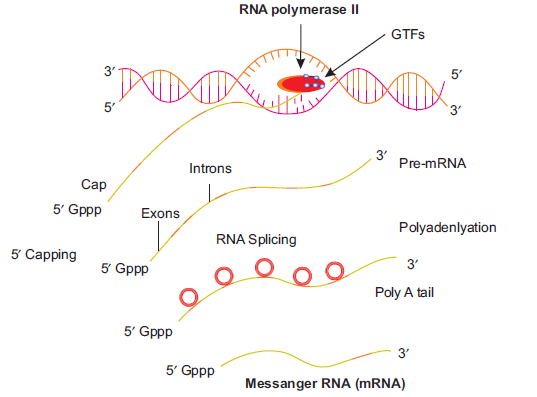
Figure 6.7: Transcription in eukaryotes
ACTIVITY 3
Read the process of translation carefully and know all the important steps. After finishing your
reading, put the steps of the process of translation in separate boxes in the form of flow chart.
Start the flow chart from the production of pre-m-RNA and end with the proteins (ultimateproduct). Compare your chart with that of your classmates.
APPLICATION 6.2
1. Complete the sentence with correct word:
(a) ................... is a DNA dependent polymers.
(b) The base pairs of eukaryotic gene are ............... with the bases of transcribed mRNA.
(c) mRNA coding information for more than one gene is called ...................
(d) ................... is a process of adding poly A tails to pre mRNA.
(e) ................... are removed by RNA splicing.2. What is the particularity of the Transcription in Eukaryotes?
6.3 TRANSLATION/PROTEIN SYNTHESIS
6.3.1 Role of Transfer RNA in the Formation of Polypeptide Chain
Though there are specific codons on m-RNA for specific amino acids, nucleic acids (m-RNA)
and proteins (amino acids) are written in two different languages. Therefore, there has to be
a mediator that can decode the message in m-RNA and direct the formation corresponding
proteins. This is where the role of t-RNA comes into play. The primary role of transfer RNA(t-RNA) is to decode (translate, like an interpreter) the codons on m-RNA and use the message
Figure 6.8: A diagram showing t-RNA molecule linking amino acid at its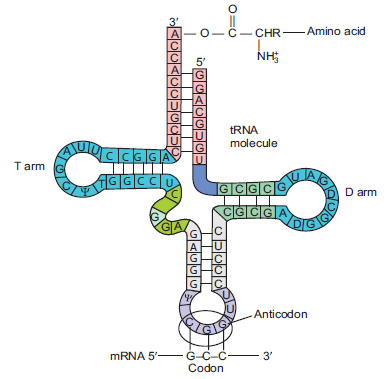
3’ end and codon on m-RNA at its anticodon site.
in codons to direct the process of synthesising polypeptide chain. Thus, t-RNA acts as an
adaptor or intermediaries. Since interpretation of the language between m-RNA and aminoacids is involved, the process of protein synthesis is called translation.
During translation, t-RNA links to a specific amino acid at its 3’ end giving rise to charged
aa-t-RNA, while the opposite end (anti-codon region) recognizes a particular codon in the
m-RNA (Figure 6.8). Depending upon the interaction between codons in m-RNA and specific
charged aa-t-RNAs, polypeptide chain (long amino acids) are synthesized during translation.
Transfer RNA is composed of 73–93 nucleotides, 10 of which are modified from the standard
4 nucleotides of RNA (A, G, C, and U) (Figure 6.8). Because of complementary base pairing,
the various t-RNAs become folded in a similar way to form a structure that can be drawn intwo dimensions as a cloverleaf.
6.3.2 The Role of Messenger RNA in the Formation of Polypeptide Chain
During transcription, the genetic information in DNA is copied and encoded in the intermediate
product called messenger RNA (m-RNA), which along with t-RNA will be used by ribosome
for protein synthesis/translation (Figure 6.9). Thus, the primary role of messenger RNA is to
carry the genetic information copied from DNA in the form of a series of codons (three-basecode), each of which specifies a particular amino acid.
Figure 6.9: (A) A simplistic diagram representing transcription and translation.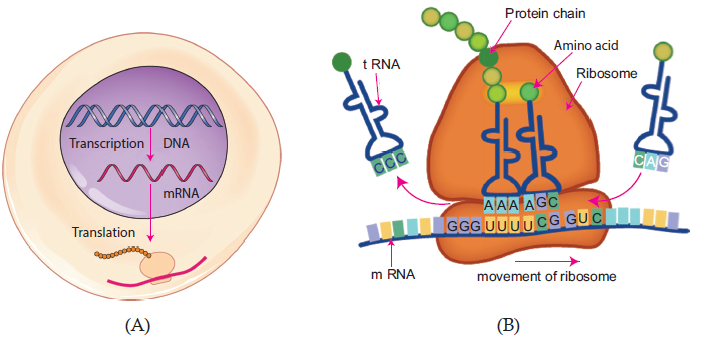
(B) A diagram showing m-RNA carrying genetic information copied from DNA in the form ofcodons. Examples: UUU, UCG codons are shown in the diagram
The series of codons in m-RNA code for specific amino acids. For example, as shown in
Figure 6.2, UUU codon will code for phenylalanine amino acid; similarly, UCG codon willcode for serine amino acid.
6.3.3 Role of Ribosomes in the Formation of Polypeptide Chain
Ribosomes are machines that carry our protein synthesis or translation. The main role of
ribosomes is to orient the m-RNA and amino acid carrying t-RNAs in such a position that the
genetic code can be read accurately and catalyse peptide bond formation.
Ribosomes are particles made up of ribosomal RNA (r-RNA) and proteins. In prokaryotes, they
are present in cytoplasm, while in eukaryotes they occur both free in the cytosol and bound to
membrane of the nuclear envelope. Mitochondria and chloroplast also have ribosomes.
Generally, a ribosome is composed of two dissociable subunits called the large and small subunits.
In prokaryotes (bacteria), ribosome has a sedimentation coefficient of 70S; it is made up by 30S
small subunit and 50S large subunit (Figure 6.10). In eukaryotes, ribosome has a sedimentationcoefficient of 80S; it is made up of 40S small unit and 60S large unit.
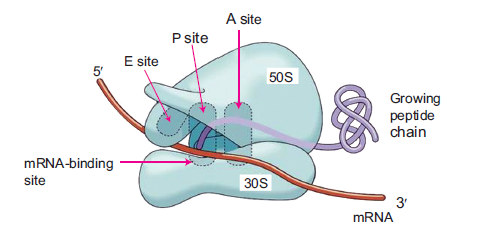
Figure 6.10: A bacterial ribosome
There are four important sites in the ribosome. These four sites are particularly important during
protein synthesis (Figure 6.10). These are:
(a) Messenger RNA-binding site: It is the site that binds m-RNA.
(b) A (aminoacyle) site: It is the site that binds each newly incoming t-RNA with its attached
amino acid.
(c) P (peptidyl) site: It is the site where the t-RNA carrying the growing polypeptide chain
resides.
(d) E (exit) site: It is the site from which t-RNAs leave the ribosome after they have dischargedtheir amino acids.
6.3.4 The Way DNA Codes for Polypeptides is Central to Understanding how Cells andOrganisms Function
The central dogma of molecular biology is an explanation of the flow of genetic information,from DNA to RNA, to make a functional protein within a biological system.
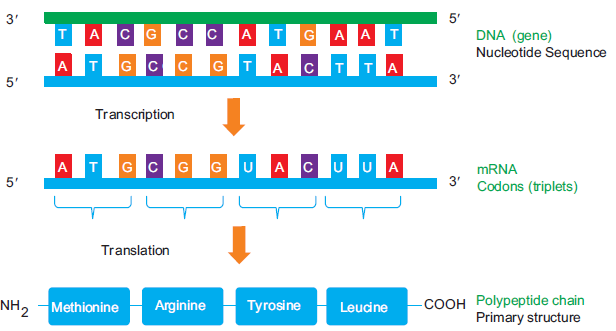
Figure 6.11: Central Dogma-information flow in a biological system
Once a DNA is transcribed into RNA (m-RNA), the genetic code (codon) in an m-RNA
specifies the amino acids that are assembled during protein synthesis to make polypeptides.
That is why the way DNA codes for polypeptides is central to our understanding of how cells
and organisms function.
More specifically, nucleotide sequence in a DNA molecule forms a gene. This particular gene
is then transcribed and translated into a specific polypeptide chain (proteins). In other words,
the nucleotide sequence in a DNA determines the sequence in which amino acids are linked
together when proteins are synthesized (Figure 6.11).
Furthermore, the properties and functions of proteins are determined by the structure of proteins.
The primary structure (simple sequence of amino acids) determines its three dimensional shape
and, therefore, its properties and functions. For example, the primary structure of an enzyme
determines the shape of its active site. And the shape of this active site will consequentlydetermine the substrate with which it can bind.
For proteins to become biological functional, they have to be expressed i.e., two molecules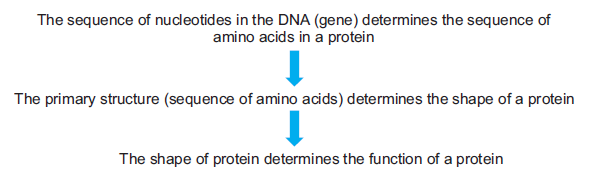
must bind to each other. For examples:–An antibody protein must bind to an antigen to trigger
an immune response; an enzyme protein must bind to a substrate to catalyze a reaction. The
binding of two molecules involves the two molecules to recognize each other and form a series
of non-covalent bonds. Recognition of two molecules for each other is termed “structuralcomplementarity.” It can be compared with a key fitting into a lock.
6.4 TRANSLATION IN BACTERIA
Translation is the production of protein molecules (polypeptides) by cellular ribosomes with
the help of information present on the m-RNA. The m-RNA and protein molecules are like
two languages written with different types of letters. The language by which the information
on m-RNA is written has to be translated into the language of amino acids in order to use it
to direct the sequential assembly of amino acids into a polypeptide chain. That is the reasonwhy protein synthesis is appropriately referred to as translation.
Charging of t-RNA
Prior to translation, each t-RNA molecule must be attached to the correct amino acid. Therefore,
the covalent linking of a specific amino acid to the 3’ end of the correct t-RNA by the enzyme
aminoacyl-t-RNA synthetase is called charging of t-RNA. An enzyme aminoacyl-t-RNA
synthetase catalyzes the linking of amino acids to their corresponding t-RNAs via an ester
bond, accompanied by the hydrolysis of ATP to AMP and pyrophosphate. This process is a
critical step in translation as it determines the accuracy of translation.Charging of t-RNA occurs in two steps:
1. ATP+ amino acid → aminoacyl-AMP + PPi
2. Aminoacyl-AMP + t-RNA → aminoacyl-t-RNA + AMP
6.4.1 The Process of Translation
The process of translation basically consists of three major stages: (1) Initiation, (2) Elongationand (3) Termination (Figure 6.12).
1. Initiation: It is the stage where m-RNA is bound to the ribosome and positioned itself
for proper translation. It can be further subdivided into three steps:
(a) Binding of initiation factors: The initiation factors along with GTP first bind to 30S
subunit.
(b) Binding of m-RNA and t-RNA: Now the m-RNA and the charged t-RNA with the
first amino acid bind to the 30S ribosomal subunit.
(c) Formation of 70S Subunit: The 30S ribosomal subunit now binds to a free 50S
ribosomal subunit forming the 70S initiation complex. During this step, all the
initiation factors are released.
2. Elongation: It is the stage where amino acids are sequentially joined together to form a
polypeptide chain via peptide bonds. The sequence of polypeptide chain is formed in an
order specified by the arrangement of codons in m-RNA. Elongation can be subdivided
into three steps:
(a) Binding of an aminoacyl-t-RNA: The binding of an aminoacyl-t-RNA to 70S
ribosome brings a new amino acid into a position on the ribosome that can be joined
to the polypeptide chain. In bacteria, normally the first incoming aminoacyl-t-RNA
is N-formylmethionine (fMet).
(b) Peptide bond formation: The newly incoming amino acid is linked to the growing
polypeptide chain by peptide bond formation.
(c) Translocation: It is a process in which the m-RNA is moved by a distance of threenucleotides (codon) to bring the next codon on the ribosome.
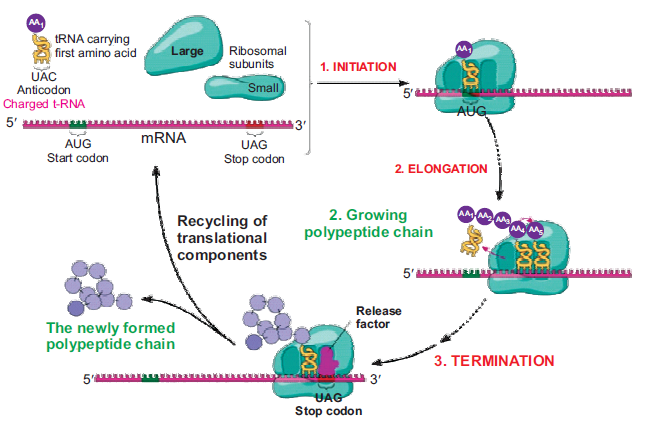
Figure 6.12: The process of Translation
3. Termination: It is the process of ending translation. At this stage, the newly formed
polypeptide chain and the m-RNA are released from the ribosome. Termination happens
when the ribosome comes across one of the stop codons (UAG, UAA, UGA) on the
m-RNA. The stop codons are not recognized by any t-RNA; rather, they are recognized by
release factors (RF). These release factors along with GTP bind on the stop codons and
initiate the termination process. RF1 recognizes UAA and UAG, while RF2 recognizesUAA and UGA.
Polyribosomes/Polysomes
Polyribosomes or polysomes are also known as ergosomes. It was first discovered and
characterized by Jonathan Warner, Paul Knopf, and Alex Rich in 1963. As the name
goes, ‘poly’ means many. Therefore, polyribosomes are complex of an m-RNA molecule
and multiple ribosomes that are simultaneously translating it.
Normally a single ribosome does not alone translate the m-RNA. But there are multiple
ribosomes, probably about 50 ribosomes, which come and bind on the m-RNA one after
the other as the preceding ribosomes move from the initiation codon (5’ end) towards 3’
end until it comes across terminating codons. Most importantly, these multiple ribosomes
that bind on m-RNA simultaneously carry on the translation process (Figure 6.13). As
a result, polyribosomes enable a large number of polypeptides to be produced fasterand efficiently from a single m-RNA compared to a single ribosome translating alone.
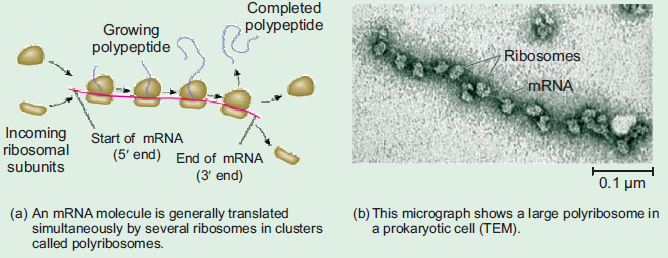
Figure 6.13: Polyribosomes
6.5 TRANSLATION IN EUKARYOTES
Translation in eukaryotes is much more complex than that of the translation in bacteria.
However, the basic process of bacterial translation remains the same in eukaryotes. Some of
the major differences between the bacterial and eukaryotic translations are:
1. Initiation:
(a) The first amino acid that binds on AUG start codon is methionine amino acid rather
than N-formylmethionine.
(b) It has 80S ribosomal initiation complex instead of 70S ribosomal initiation complex;
it is formed by small 40S ribosomal subunit and 60S ribosomal subunit.
(c) There are many more initiation factors (eIFs) in eukaryotes than in bacteria.
(d) A complex of 40S ribosomal subunit + charged Met-t-RNA + several eIFs + eIF
proteins move along the m-RNA and scan for the AUG start codon. This process is
called Scanning Model for initiation. Once the AUG start codon is located, the 60S
ribosomal subunit joints the complex to form 80S ribosomal initiation complex.
2. Elongation: Elongation in eukaryotes requires about nine eukaryotic elongation factors
(eEFs).
3. Termination: The process of termination is similar to that in bacteria. But in the case of
eukaryotes, a single release factor, called eukaryotic release factor 1 (e-RF1), recognizes
all the three stop codons (UAG, UAA, UGA). And the e-RF1 also stimulates the processof termination.
ACTIVITY 4
Watch video clips using the Internet on the process of protein.
Synthesis: Using chart papers of different colours, prepare a model of protein synthesis. You
should be very particular about shapes of structure made like with student of DNA, tRNA. You
may use the following internet links: -orAPPLICATION 6.3
1. Complete the sentence with correct word:
(a) ................... is a DNA dependent polymers.
(b) The base pairs of eukaryotic gene are ............... with the bases of transcribed mRNA.
(c) mRNA coding information for more than one gene is called ...................
(d) ................... is a process of adding poly A tails to pre mRNA.
(e) ................... are removed by RNA splicing.2. What is the particularity of the Transcription in Eukaryotes?
6.6 THE EFFECT OF CHANGE IN GENETIC CODE ON THE STRUCTURE OF
PROTEIN DURING PROTEIN SYNTHESIS
ACTIVITY 5
Make a minilab report to demonstrate how gene mutations affect protein synthesis using a
sequence of bases of one strand of an imaginary DNA molecule. You may use the examples
shown in the text below.
Research and present the findings in journal form on how genetic drugs can be used to stop the
expression of genetic diseases with specific reference to how they may interfere with activities
of nucleic acids in the nucleus and the cytoplasm of the cell. You may look upto research
papers, Internet and magazines
Mutations are changes in genetic codons caused by changes in nucleotide bases. Some mutations
do not have much effect. However, some mutations can have a huge effect on genetic code,
which can eventually affect the proteins they code for. The proteins produced in turn can havea profound effect on cellular and organismal function.
Mutations occur in two ways:
A. A base-pair substitution: It is a change from one base pair to another base pair in DNA.
B. Base-pair insertions or deletions: It is a change in which a base-pair is either incorrectlyinserted or deleted in a codon.
(A) A Base-Pair Substitution
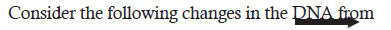
This change in base pair brings changes in the m-RNA codon from one purine to the other
purine. In this case, the m-RNA codon is changed from 5’-AAA-3’ (lysine) to 5’-GAA-3’
(glutamic acid). This is missence mutation.Now look at the changes in DNA from
This change in base-pair in DNA results in change in m-RNA codon from 5′-AAA-3′ (lysine) to
5′-UAA-3′, which is a stop codon. This is a nonsense mutation. It causes premature termination
of polypeptide chain synthesis, thereby releasing shorter polypeptide fragments than the normal
length of polypeptide fragments during translation. These shorter fragments are often nonfunctional.
A silent mutation results from AT-to-GC transition mutation that changes the codon from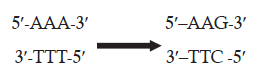
5′-AAA-3′ to 5′-AAG-3′. Both of these codons 5′-AAA-3′ to 5′-AAG-3′ specify the same amino
acid, lysine. It is worth mentioning that silent mutation often occurs by changes at the thirdwobble position of a codon. Refer wobble hypothesis in Genetic code.
(B) Base-Pair Insertions or Deletions
ACTIVITY 6
Consider a statement that is made up of the following words each having three letter like genetic
code.
RAM HAS RED CAP
If we insert a letter B in between HAS and RED and rearrange the statement, it would read as
follows:
RAM HAS BRE DCA P
Similarly, if we now insert two letters at the same place, say BE. Now it would read.
RAM HAS BIR EDC AP
Now we insert three letters together, say BIG. The statement would read.
RAM HAS BIG RED CAP
The same exercise can be repeated, by deleting the letters R, E and D, one by one and rearranging
the statement to make a triplet word.
RAM HAS EDC AP
RAM HAS DCA P
RAM HAS CAP
The conclusion from the above exercise is very obvious. Insertion or deletion of one or two
bases changes the reading frame from the point of insertion or deletion. Insertion or deletion of
three or its multiple bases insert or delete one or multiple codon hence one or multiple amino
acids and reading frame remains unaltered from that point onwards, mutations are referred toas frame-shift insertion or deletion mutations.
6.7 EFFECTS OF ALTERATION OF NUCLEOTIDE SEQUENCE
Change in Nucleotide (Mutation) Sequence Leads to Change in Polypeptides
Amino acids (proteins) are the ultimate product of the nucleotide sequence present in genes
(DNA). Thus, any change in the nucleotide sequence of a gene can result into producing
wrong or different polypeptide chain. In other words, gene mutation is a change in sequenceof nucleotides that results in change in the synthesis of polypeptide chains.
One of the best examples is Sickle-cell anaemia. In this disease, the nucleotide “T” in the DNA
sequence is replaced by “A” nucleotide. The minor substitution in the nucleotide sequence is
transcribed as a mutant codon on the m-RNA. And during translation, due to mutant codon
on the m-RNA, valine is synthesized instead of glutamic acid. Valine distorts red blood cellsand cause sickle-cell anaemia. You will be studying it in the next section.
Another example is Albinism. Albinism occurs due to mutation in the gene for tyrosinase, an
enzyme which converts tyrosine to DOPA (dihydroxyphenylalanine) (Figure 6.14). Melanin,
skin pigment, is derived from DOPA. Melanin absorbs light in the ultraviolet (UV) range and
protects the skin against harmful UV radiation from the sun. People with albinism produce
no melanin. Therefore, they have white skin, white hair, eyes with red iris, and they are verysensitive to light.
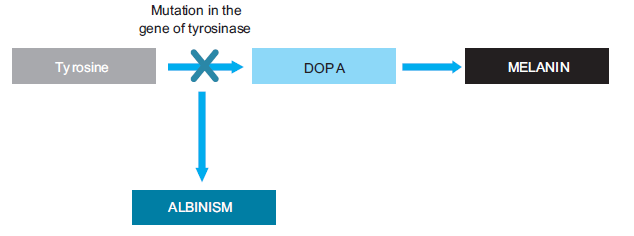
Figure 6.14: Mutation of tyrosinase gene results in albinism, lack of melanin pigment
Sickel Cell Anaemia

Cause
The mutation causing sickle cell anaemia is a single nucleotide substitution (A to T) in the
DNA of haemoglobin coding gene. The change in a single nucleotide is transcribed as a codon
for valine amino acid (GUG) on the m-RNA instead of glutamic acid (GAG) (Figure 6.15).
Eventually, due to change in the codon, valine amino acid is translated instead of glutamic
acid at the 6th position from N-terminus of the haemoglobin polypeptide chain (Figure 6.16).This defective form of haemoglobin in persons with sickle cell anaemia is referred to as HbS.
Figure 6.15: A single nucleotide substitution in haemoglobin gene resulting into replacement of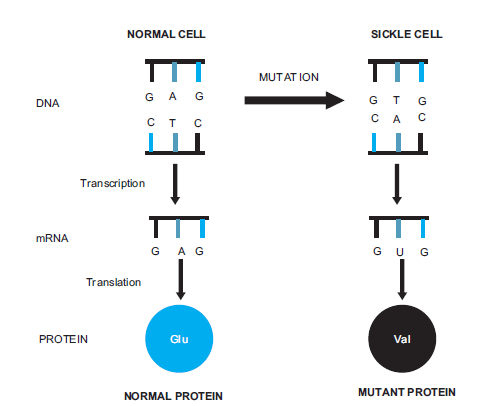
glutamic acid by valine amino acid
Figure 6.16: A diagram showing replacement of glutamine (Glu) by valine (Val) at 6th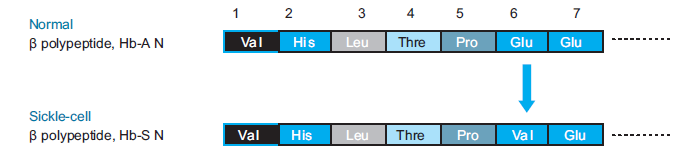
position from N-terminus in the sickled haemoglobin polypeptide
The amino acid valine makes the haemoglobin molecules stick together, forming long fibreswhich convert the normal disc-shape of red blood cells into sickle-shaped red blood cells.
Symptoms
The sickled red blood cells are fragile and break easily, resulting in the anaemia. Normal red
blood cells normally squeeze and pass through blood capillaries smoothly. However, sickled
cells are not flexible and therefore have the tendency to get clogged in capillaries (Figure 6.17).As a result, blood circulation is impaired and tissues become deprived of oxygen. Oxygen
deprivation occurs at the extremities, the heart, lungs, brain, kidneys, gastrointestinal tract,muscles, and joints.
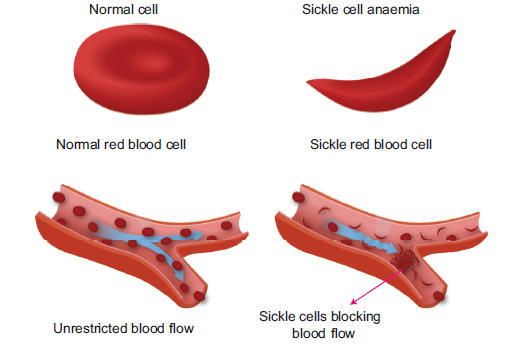
Figure 6.17: Difference between normal and sickle red blood cells
Sickle cell anaemia is an autosomal recessive disorder that affects 1 in 500 African-Americans,
and is one of the most common blood disorders and in the United States. By autosomal disorder,
it means that in order for full disease symptoms to manifest in an individual they must carry two
copies (homozygous genotype = SS, HbS & HbS) of the HbS gene (Figure 6.18). However, the
individuals who are heterozygous (genotype = AS, i.e., HbA and HbS) have what is referred
to as sickle cell trait, a phenotypically dominant trait.
Although heterozygous (AS) individuals are clinically normal, their red blood cells can sickle
under very low oxygen pressure. Their red blood cells may sickle when they are at high altitudesin airplanes with reduced cabin pressure.
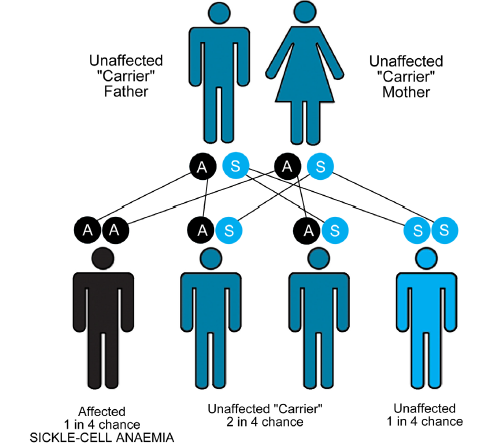
Figure 6.18: A diagram showing sickle-cell anaemia as autosomal recessive disorder
APPLICATION 6.3
1. Complete the sentence with correct word:
(i) ................. distorts red blood cells and cause sickle-cell anaemia.
(ii) ................. people are sensitive to light.
(iii) Mutations are of two types ................. and ................. .
(iv) Sickle cell anaemia is an ................. disorder.2. What are the symptoms and complications of sickle cell anemia?
6.8 SUMMARY
• Genetic Code is the set of rules by which information is encoded in genetic material
(DNA or RNA sequences) is translated into proteins (amino acid sequences) by living cells.
• A codon is made up of three nucleotides or triplets. Out of 64 codons, 61 codons are
sense codons and 3 codons are non-sense codons.
• Genetic code is almost universal; it shows degeneracy.
• It is through genetic code that the genetic information found in m-RNA is translated to
mature functional proteins.
• DNA molecule is a stable structure and replicates accurately in order to avoid any mutation
or change in nucleotide sequences in DNA.
• Transcription is the process of copying information from one strand of DNA into a
single stranded RNA (mRNA).
• A transcription unit in DNA is composed of a promoter, RNA coding sequence, and a
terminator.
• The process of transcription in bacteria includes —
♦ Initiation — a process of initiating transcription where a complex of RNA polymerase
with sigma factor binds at the promoter.
♦ Elongation — the process in which RNA polymerase synthesizes a complementary
RNA sequence of the DNA template strand.
♦ Termination — the process of ending transcription; and it can be carried out either
in rho dependent manner or rho independent manner.
• The process of transcription in eukaryotes involves —
♦ Initiation involves a complex of RNA polymerase II and general transcription factors.
♦ Elongation is similar to that of bacteria. But eukaryotic genes do not have terminator
sequences.
♦ The newly formed pre-m-RNA has to undergo RNA processing.
• Translation is the production of protein molecules (polypeptides) by cellular ribosomes
with the help of information present on the m-RNA.
• The covalent linking of a specific amino acid to the 3’ end of the correct t-RNA by
the enzyme aminoacyl-t-RNA synthetase is called charging of t-RNA.
• Translation in bacteria includes —
♦ Initiation is a stage where m-RNA is bound to the ribosome and positioned itself for
proper translation. It involves three steps.
♦ Elongation is a stage where amino acids are sequentially joined together to form a
polypeptide chain via peptide bonds.
♦ Termination is the process where the newly formed polypeptide chain and the m-RNA
are released from the ribosome.
♦ Polyribosomes are complex of an m-RNA molecule and multiple ribosomes that
are simultaneously translating it. It enables a large number of polypeptides to beproduced faster and efficiently.
• Translation in eukaryotes includes —
♦ Initiation differs from that of bacteria by: the first amino acid is methionine; it has
80S initiation complex; it locates start codon by scanning model for initiation.
♦ Elongation is characterized by the involvement of nine eukaryotic elongation factors.
♦ Termination codes are recognized only by e-RF1.
♦ Change in genetic code is known as mutation.
♦ Mutation is of two types: A base-pair substitution and base-pair insertions or deletions.
♦ Some mutations do not have much effect such as silent mutation. However, some
mutations can have a huge effect on genetic code such as frameshift mutation.
♦ Any change in the nucleotide sequence of a gene can result into producing wrong
or different polypeptide chain. The outcomes can be detrimental to the affected
organisms.♦ Example: Sickle cell anaemia; albinism.
6.9 GLOSSARY
• Albinism: It is a disease caused by alteration of nucleotide sequence. It occurs due to
mutation in the gene for tyrosinase, an enzyme which converts tyrosine to DOPA.
• Charging t-RNA: It is the process of attaching the correct amino acid to t-RNA with
the help of aminoacyl-t-RNA synthetase enzyme.
• Degeneracy: The coding of the same amino acid by multiple codons. Example:UUU
and UUC codons code for the same specific phenylalanine amino acid.
• Frameshift mutation: It is a gene mutation in which addition or deletion of one basepair
shifts the m-RNA’s downstream reading frame by one base so that incorrect amino
acids are added to the polypeptide chain after the mutation site.
• Missense mutation: It is a gene mutation in which change in base-pair (nucleotide
sequence) of DNA results in change in an m-RNA codon, which codes for different
amino acid.
• Polyribosomes: They are complex of an m-RNA molecule and multiple ribosomes that
are simultaneously translating it.
• Rho protein: It is a protein that binds to the terminator sequence and RNA polymerase
to end the process of transcription in bacteria.
• RNA processing: It is the process where pre-m-RNA undergoes modification to become
a functional m-RNA.
• Sickle cell anaemia: The mutation causing sickle cell anaemia is a single nucleotide
substitution (A to T) in the DNA of haemoglobin coding gene. The change in a single
nucleotide is transcribed as a codon for valine amino acid (GUG) on the m-RNA instead
of glutamic acid (GAG).
• Stop codon: It is a nonsense codon, meaning it does not specify any amino acid. It rather
stops translation.
• Transcription: It is the process of copying information from one strand of DNA into a
single-stranded RNA (m-RNA).
• Translation: It is the production of protein molecules (polypeptides) by cellular ribosomes
with the help of information present on the m-RNA.
• Translocation: It is a process in which the m-RNA is moved by a distance of three
nucleotides (codon) to bring the next codon on the ribosome (A site).
• Wobble hypothesis: The reading of two or more different codons by the same t-RNA
molecule. Example: The two different leucine codons (CUC, CUU) can be read by thesame leucine t-RNA molecule, contrary to regular base-pairing rules.
END UNIT ASSESSMENT 6
I. Choose whether the following statements are True (T) or False (F)
1. Genetic code is composed of A, C, G, and T nucleotides.
2. The main role of t-RNA is to decode the codons on m-RNA.
3. The main role of m-RNA is to carry genetic information in a series of codons.
4. Ribosomes are made up only by proteins.
5. TATA box is found 10 base pairs downstream from +1 start site.
6. RNA polymerase doesn’t need any factor to initiate transcription.
7. Hairpin loop structure is formed in rho dependent terminators.
8. Pre-m-RNA needs to undergo RNA processing to become functional m-RNA.
9. In prokaryotes, the first amino acid to bind at the P-site is N-formylmethionine.
II. Multiple Choice Questions
1. Sickle-cell anaemia is caused due to change in
(a) Nucleotide T by A in the DNA (b) Nucleotide A by T in the DNA.
(c) Nucleotide G by U in the DNA (d) Nucleotide U by G in the DNA.
2. Which of the following are the characteristics of genetic code?
(a) Triplet code (b) Almost Universal
(c) Nonoverlapping (d) All of these.
3. The wrong stop codon is
(a) UUA (b) AUU
(c) UAG (d) UGA
4. The word “wobble” means
(a) Jumping (b) Synthesis
(c) Unsteady (d) Stable
5. Which of the following is located in the upstream of a bacterial gene?
(a) Promoter (b) Terminator
(c) RNA-coding sequence (d) None of the above
6. RNA polymerase I doesn’t catalyze the synthesis of
(a) 28S molecule (b) 5S molecule
(c) 5.8S molecule (d) 18S molecule
7. Which of the following components is not involved in eukaryotic transcription?
(a) General transcription factors (b) RNA polymerase II
(c) Sigma factor (d) Enhancers
8. Which of the following are related to eukaryotes?
(a) RNA Processing (b) Introns & exons
(c) Poly (A) tail (d) All of these
9. Scanning model is related to
(a) Charging of t-RNA (b) Initiation
(c) Elongation (d) Termination
10. In sickle-cell anaemia, valine amino acid replaces
(a) Serine (b) Threonine
(c) Glutamic acid (d) Tyrosine
III. Long Answer Type Questions
1. In your own words, state features of a genetic code.
2. Describe the process of transcription in bacteria.
3. Using diagrams, compare the process of bacterial and eukaryotic transcriptions.
4. Describe the process of translation in bacteria.
5. State the roles of t-RNA, m-RNA, and ribosomes in the formation of polypeptides.
6. What is sickle-cell anaemia? Explain its cause and symptoms.
7. In Genetic code (Figure 6.2), CUU codes for leucine (leu) amino acid. If we change
the third letter of CUU i.e., U with C, A, G, which amino acid will the changedcodon code for during translation?
8. UUU codon codes for phenylalanine (Phe). If we change the third base “U” with
C, A, G, which amino acid will the changed codon code for during translation?
9. During translation, what will happen if there is mutation on a codon UAU (codes
for tyrosine) where the third letter “U” is replaced by either one of the bases A or Gor C?
10. State that ribosomes provide surface area for the attachment of mRNA during
polypeptide synthesis.
11. Construct a flow chart, in proper sequence, for the stages of transcription and
translation.
12. Using the evidence, predict the effect of change in genetic code on the structure of
the protein manufactured during protein synthesis.
13. Briefly describe the alteration of nucleotide sequence attacking the deadly AIDS.Also show how it can be an essential step towards poverty alleviation.